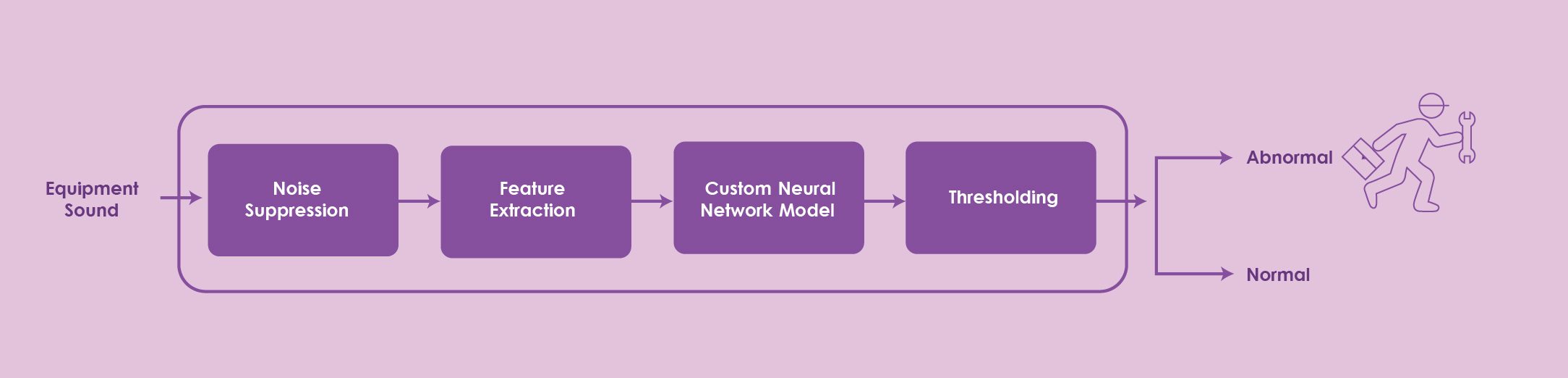
Real-time Noise Suppression (IGN-RNS)
After
Before


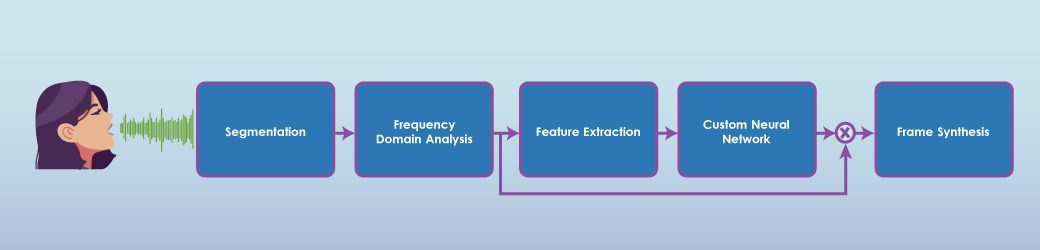








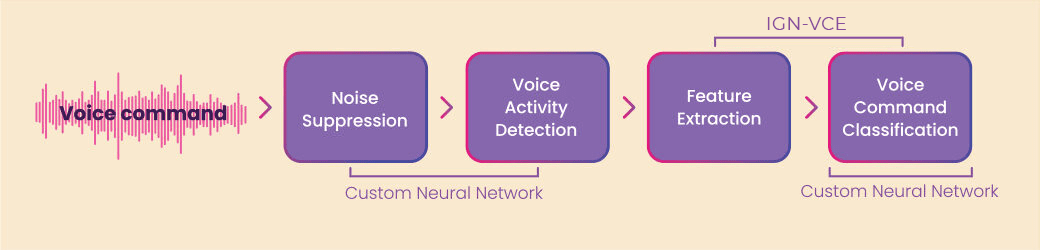
Voice Command Engine (IGN-VCE)











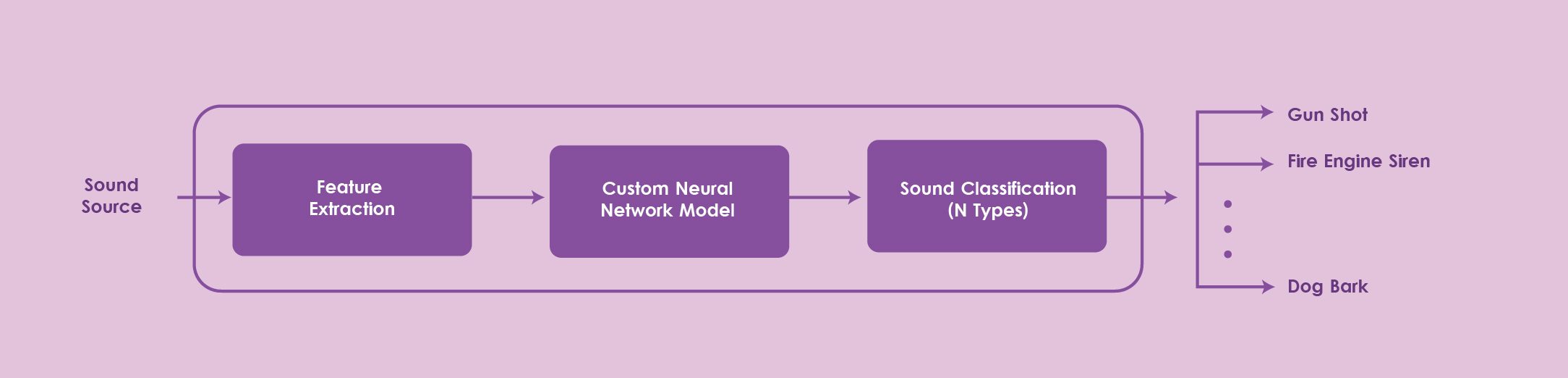
Sound Event Classification (IGN-SEC)