
Introduction
Banking operations call for the processing of thousands of cheque leaves per day; this is often done in a manual fashion, consumes large amounts of time, and suffers from susceptibility to human errors. Optical Character Recognition or OCR is a technique wherein structured text is automatically interpreted by a computing system. This blog explores different procedures for extracting relevant fields from the face of a cheque leaf using OCR methods supported by AI algorithms.
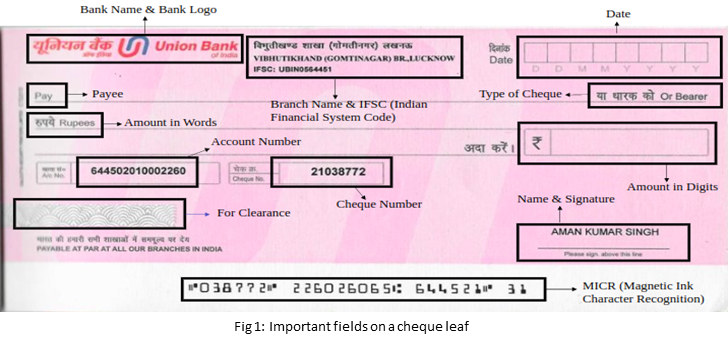
Cheque Leaf
Once you open an account with a bank, you are provided with a chequebook containing several cheque leaves. Each individual piece of paper from the chequebook is what is referred to as a cheque leaf.
Dataset
A dataset with more than 1,000 original cheque leaf images from various banks was created. This dataset contained actual cheques as well as cancelled cheques. To augment the original data corpus, different augmentation techniques have been used to enhance the count of training image samples.
The dataset was labeled using LabelImg (Python package used for annotating data) and corresponding .txt of the image annotation file was created. The list of classes includes Name, IFSC, Account number as the class labels.


Workflow: Data Detection on cheque leaf
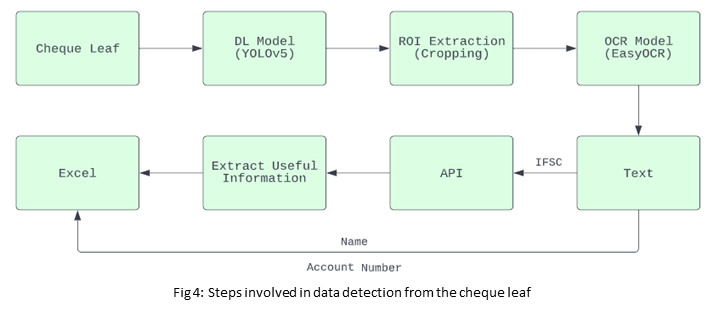
Object detection [1] is a computer vision technique for locating instances of objects in images or videos. Detection algorithms typically leverage machine learning or deep learning to produce meaningful results. When humans look at images or videos, they can recognize and locate objects of interest within a matter of moments. The goal of object detection is to replicate this intelligence using a computer. In that regard, YOLOv5[2] is one among the well-known object detection techniques in deep learning; this model is used to address text detection on the cheque leaf.
Architecture of YOLOv5
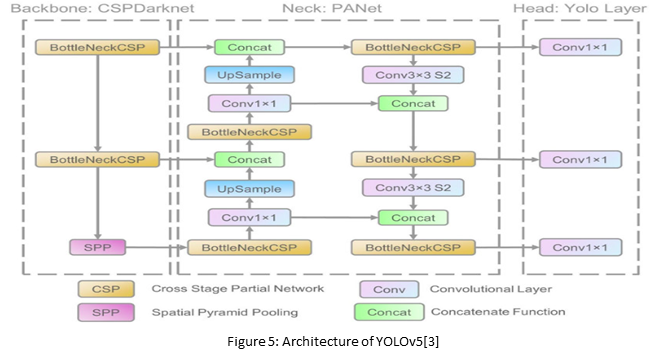
The network architecture of YOLOv5 consists of three parts:
1. Backbone: CSPDarknet
2. Neck: PANet
3. Head: Yolo Layer
The data is first input to CSPDarknet for feature extraction, and then fed to PANet for feature fusion. Finally, Yolo Layer outputs detection results (class, score, location, size).
Result after passing a cheque leaf through YOLOv5
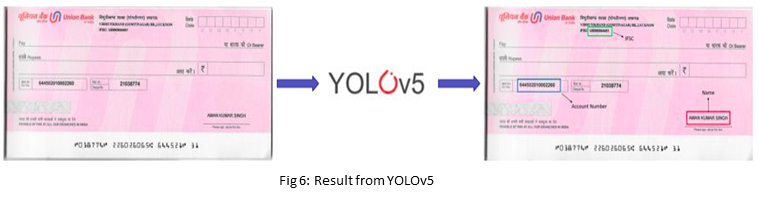
The fields detected by YOLOv5 will be passed through the OCR stage of the pipeline.
OCR
OCR [4] stands for ‘Optical Character Recognition’. It is a technology that recognizes text within a digital image. It is commonly used to recognize text in scanned documents and images. OCR software can be used to convert a physical paper document or an image into accessible text.
Here, EasyOCR is used as the OCR model.
After getting the resultant image each class needs to be cropped and passed through the OCR model.
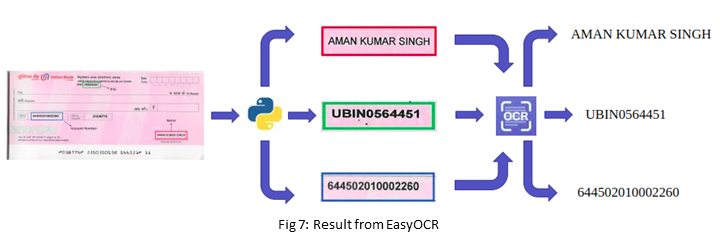
After extracting the text, the IFSC field will pass through Ignitarium’s Bank API to fetch the remaining details.
Bank API
An application programming interface[5] (API) is a way for two or more computer programs to communicate with each other. It is a type of software interface, offering a service to other pieces of software.
APIs [6] are needed to bring applications together in order to perform a designed function built around sharing data and executing pre-defined processes. They work as the middleman, allowing developers to build new programmatic interactions between the various applications used by people and businesses daily.
Ignitarium’s Bank API accesses publicly available bank databases maintained by the Reserve Bank of India (RBI) and performs custom queries to lookup relevant information using the IFSC code as the input key.
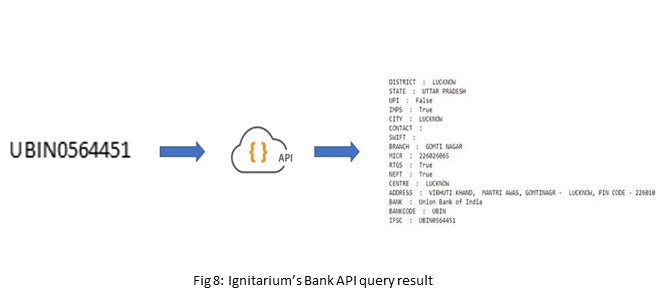
Approach
The dataset was divided into training and validation with the ratio 80% – 20% respectively. The model was trained using PyTorch.
The first method, which involved giving a cheque leaf directly to an OCR model, produced results but also extracted unnecessary data. Additionally, an OCR model will struggle to read some text, particularly the Bank Name and Branch Address because different banks use different writing styles and fonts. Additionally, since the Branch Address is too long, there is a chance that the OCR model will not correctly read the complete address.
Secondly, template matching techniques can be used for extracting details. It will be challenging to consider all banks as different banks use different templates, and in some cases, the same bank uses a different kind of cheque template (for a client, industry, etc.)
Spacy-NER model and YOLOv3 were utilized as the third and fourth approaches, but the outcome was not very good.
In the final approach chosen, the object detection model (YOLOv5) was employed as a front end to the OCR model, resulting in the desired accuracy levels being met
Results
After passing a cheque leaf through the pipeline:
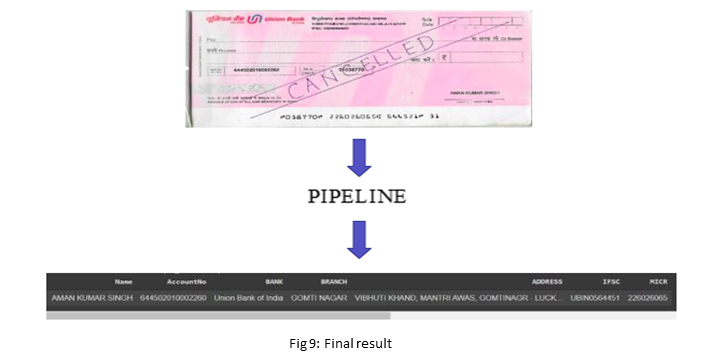
As multiple cheques were processed by the pipeline, results were appended to an Excel sheet.

References
1. https://en.wikipedia.org/wiki/Object_detection
2. https://github.com/ultralytics/yolov5



























