Performance Evaluation is important to do comparative study of different algorithms and decide which algorithm is better than others. There are two types of evaluation methods, which are Objective Evaluation and Subjective Evaluation. Objective Evaluation is quantitative evaluation based on statistical criteria, whereas Subjective Evaluation refers to evaluation setups where human subjects quantify the performance and quality of the algorithm.
This section explains the different objective and subjective methods/metrics used for evaluating the performance of the different Adaptive filter Algorithms. The different adaptive algorithms are Least Mean Square (LMS), Normalized Least Mean Square (NLMS), Recursive Least Square (RLS), Variable Least Mean Square (VLMS), Affine Projection and Kalman filter algorithms.
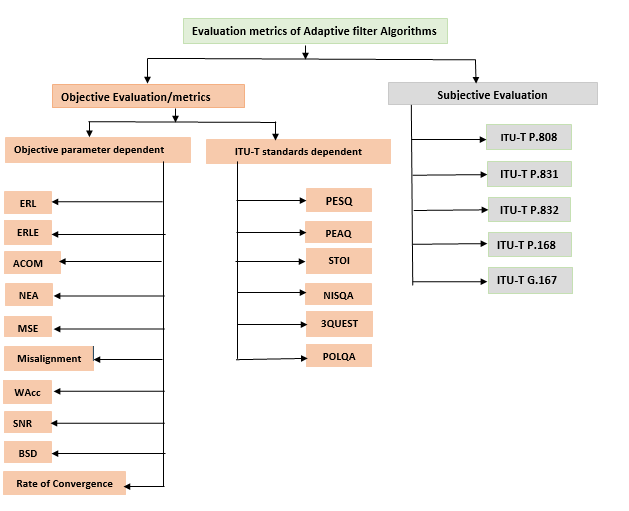
1.1 Objective Evaluation/Objective Metrics
1. Echo Return Loss (ERL) – Measured in dB, ERL is the ratio of receive-out and send-in power. ERL measures receive-out signal loss when it is reflected as echo within the send-in signal. According to International Telecommunications Union’s (ITU’s) specifications, the ERL of the echo path should be over 6dB. For acoustic ECs (Echo Cancellation), the ERL could be as bad as –12dB. The infinite ERL indicates the digital termination or on-hook condition.
ERL (in dB) = 10 log (Pd / Pin)
WherePd is the power of the received signal
Pin is the power of the input signal.
2. Echo Return Loss Enhancement (ERLE) – ERLE is one of the most important metrics commonly used to evaluate the performance of the echo cancellation algorithms. Measured in dB, it is the ratio of input desired signal power and residual error signal immediately after echo cancellation\echo suppression. It measures the amount of loss introduced by the adaptive filter alone and depends on the size of the adaptive filter and the algorithm design. Two quantities are considered with ERLE are the convergence time and near-end attenuation in EC’s. ERLE should be in the range of (45dB, -40dB).
ERLE (in dB) = 10 log (Pd / Pe)
WherePd is the power of the desired signal
Pe is the power of the error signal.
3. Combined Loss (ACOM) – This is the total amount of echo suppression, which includes the echo return loss, echo return loss enhancement and non-linear processing loss (if present).
ACOM = AECHO + ACANC + ANLP
Where AECHO is echo return loss.
ACANC is an echo return loss enhancement.
ANLP is non-linear processing loss.
4. Near-end attenuation (NEA) – This measures how much near end signal is suppressed during cancellation process in double talk scenario.
NEA (Near End Attenuation) (in dB) = 10 log (Pafter / Pbefore)
WherePafter is the signal before cancellation process.
Pbefore is the signal after cancellation process.
5. Mean square error (MSE) – It will be essential to evaluate the performance of adaptive filters, the purpose of the adaptive filter in EC (Echo Cancellation) is minimizing the Mean Square Error MSE (Mean Square Error). For stationary input and desired signals, minimizing the mean squared error (MSE) would result in the Wiener filter, which is said to be optimum in the mean-square sense.
a. LMS and NLMS adaptive algorithm: The criteria of LMS and NLMS adaptive algorithm is minimum mean square of error signal.
MSE = E{e(n)2 }
Where e(n) is the error signal
b. RLS adaptive algorithm: In RLS adaptive algorithm, 2 different errors must be considered, priori estimation error Ɛ(n) is the error occur when filter coefficients were not updated, and posteriori error e(n) is the error which occur after the weight vector is updated. The RLS algorithm depends on the least mean square i.e. (LSE) not MSE.
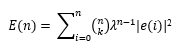
6. Misalignment/ Mis adjustment – Measures the mismatch between the true and the estimated impulse response of the receiving room.
misalignment = || h – hest || / || h ||
Where || . || denotes the l2 norm of a vector and h = [h (0),.…., h(L-1)].
7. Word Accuracy Rate (WAcc) –Word Error rate is an industry standard for measuring speech recognition accuracy using the relation WAcc = 1- WER. The number of correctly recognized words from the total number of words spoken stands for WAcc.
Word Error Rate = (Substitutions + Insertions + Deletions) / Number of Words Spoken.
8. Signal to Noise Ratio (SNR) – Measured in dB, which is another important performance criteria of adaptive filter cancellation. SNR describes the ratio of input signal to noise signal.
SNR (in dB) = 10 log (S / N)
Where S is the signal and N is the noise signal
9. Bark distortion measure (BSD) – Loudness is related to signal intensity in a nonlinear fashion. This considers the fact that the perceived loudness varies with frequency. The BSD measure for frame k is based on the difference between the loudness spectra and is computed as follows.
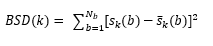
where ![]() a are the loudness spectra of the clean and enhanced signals respectively and Nb is the number of critical bands.
a are the loudness spectra of the clean and enhanced signals respectively and Nb is the number of critical bands.
10. Rate of Convergence – The rate of convergence is the number of adaptation cycles required for the algorithm to converge from some initial condition to its steady-state. The rate of convergence depends on the distinct factors as per the algorithm. e.g., The convergence of LMS adaptive algorithm depends on step-size, convergence of NLMS adaptive algorithm depends on variable step-size and convergence of RLS adaptive algorithm depends on the exponential weighting factor.
a. Convergence of the LMS adaptive algorithm: The convergence of LMS adaptive filter depends on 2 factors – the step-size (µ), which lie in the specific range.
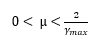
and eigenvalue spread on autocorrelation matrix X(Rx).
Where Ymax is the largest eigenvalue of autocorrelation matrix Rx.
b. Convergence of the NLMS adaptive algorithm: The convergence of NLMS adaptive filter depends on the normalized step-size (µ).
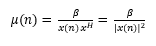
Where β is the normalized step-size with 0 < β < 2.
c. Convergence of RLS adaptive algorithm: The convergence of RLS algorithm is depends on the weighting factor λ, 0 < λ ≤ 1.
11. Perceptual Evaluation of Speech Quality (PESQ) – PESQ is designed to analyze specific parameters of audio, including time warping, variable delays, transcoding, and noise. PESQ does not consider frequency response and loudness, two especially key factors that affect the perceived quality of a telephone terminal. Audio sharpness, call volume, background noise, variable latency/lag in the call, clipping and audio interference are considered in PESQ. PESQ returns a score from -0.5 to 4.5, with higher scores showing better audio quality.
12. Perceptual Evaluation of Audio Quality (PEAQ) – The PEAQ measurement model produces several variables based on comparison between a reference signal and the same signal processed by codec. These variables are called Model Output Variables (MOV). The Objective Difference Grade (ODG) is the FFT (Fast Fourier Transform) of the difference between the FFT of the reference file versus the FFT of the degraded file. The algorithm then uses this variable along with the Model Output Variables (MOVs) to then derive a PEAQ score. In order to calculate PEAQ from ODG, we then multiply this difference with MOVs which are signal analysis parameters for which the human ear is specifically sensitive to. This allows us to tune the ODG signal to a metric that is more closely correlated with human subjective experience.
13. Short-Time Objective Intelligibility (STOI) – Intelligibility measure which is highly correlated with the intelligibility of degraded speech signals, e.g., due to additive noise, single/multi-channel noise reduction, binary masking, and vocoded speech as in CI (Continuous Integration) simulations. STOI is an objective evaluation method of machine-driven intelligibility. STOI values range from 0 to 1. STOI may be a desirable alternative to the speech intelligibility index (SII) or the speech transmission index (STI), when you are interested in the effect of nonlinear processing to noisy speech, e.g., noise reduction, binary masking algorithms, on speech intelligibility.
14. Non-intrusive Objective Speech Quality Assessment (NISQA) – It does not require a reference clean speech audio file. It is standardized from ITU-T Rec. P.800 series. NISQA supplies a prediction of the four various speech quality dimensions, those are Noisiness, Coloration, Discontinuity, and Loudness. Used in VoIP, telecommunication network.
15. Three-fold Quality Evaluation of Speech in Telecommunications (3QUEST) – This was designed to assess the background noise separately in a transmitted signal. 3QUEST returns Speech-MOS (S-MOS), Noise-MOS (N-MOS), and General-MOS (G-MOS) values. The resultant values are on a scale of 1 (bad) to 5 (excellent). G-MOS is a weighted average of the S-MOS and N-MOS. It is standardized as a ITU-T P.835 recommendation. Based on our experience, 3QUEST is the most suitable objective metric for Noise Cancellation evaluations.
16. Perceptual Objective Listening Quality Analysis (POLQA) – is an upgraded version of PESQ that supplies an advanced level of benchmarking accuracy and adds significant new capabilities for super-wideband (HD) and full-band speech signals. It is standardized as Recommendation ITU-T P.863. POLQA has the same MOS scoring scale as its predecessor PESQ, though it is for the same use case of evaluating quality related to codec distortions.
1.2 Subjective Evaluation
The following ITU-T (International Telecommunication Union – Telecommunication Standardization sector) standards can be used for speech, audio quality analysis: –
SERIES P: Telephone Transmission Quality, Telephone Installations, Local Line Networks
1. ITU-T P.808 – Subjective evaluation of speech quality with a crowdsourcing approach – Listening-only tests including the absolute category rating (ACR), degradation category rating (DCR), comparison category rating (CCR). ACR is quality of the speech is rated on five-point scores which is MOS from 1(bad) to 5(Excellent). DCR is the test where participants listen to both reference (unprocessed) and processed speech samples and rate the quality of the processed sample on the five-point degradation category rating scale which is DMOS (degradation mean opinion score). In CCR, Listen to both the reference and processed speech samples on each trial. The order of listening is random and rate the quality on comparing both which is CMOS (comparison mean opinion score). Evaluating the subjective quality of speech in noise by SMOS (speech MOS), NMOS (background noise MOS) and MOS (overall MOS).
2. ITU-T P.831 – Subjective performance evaluation of network echo cancellers – Conversational tests, Talking-and-Listening tests, and Third-party listening tests are done based on initial convergence, diversions, background noise and impairments during single-talk/double-talk.
3. ITU-T P.832 – Subjective performance evaluation of hands-free terminals – Conversational tests, Talking-and-Listening tests, and Third-party listening tests are done based on transmission of background noise, variations of loudness, impairments caused by speech gaps and echoes, dialogue capability, speech sound quality.
4. ITU-T P.168 – Digital network echo cancellers – The Steady state residual and returned echo level test, Convergence and steady state residual and returned echo level tests, Convergence test in the presence of background noise, Performance under conditions of double talk, Double talk stability test, Leak rate test, Infinite return loss convergence test, non-divergence on narrow-band signals, Stability test are covered in the ITU-T P.168 standard.
SERIES G – General Characteristics of International Telephone Connections and International Telephone Circuits
5. ITU-T G.167 –– Acoustic Echo Controllers – The following different verification tests are done under ITU-T G.168. Weighted terminal coupling loss in single talk and double talk, received speech attenuation during double talk, sent speech attenuation during double talk, received speech distortion during double talk, sent speech distortion during double talk, maximum frequency shift, break-in time, Initial convergence time, recovery time after double talk, terminal coupling loss during echo path variation, recovery time after echo path variation.
1.3 Conclusion
The adaptive filter algorithm is used in many applications such as telecommunication, radar, sonar, video and audio signal processing, Image processing, noise reduction and in many biomedical applications.
In Ignitarium, adaptive filter algorithms are used for different audio processing algorithms like Ignitarium Voice Activity Detection and Acoustic echo cancellation. We have implemented the performance framework to measure the ERL, ERLE, ACOM, Misalignment, NEA, PESQ and STOI for LMS, NLMS, Affine projection and Kalman filter adaptive algorithms.
References:
1. https://www.ripublication.com/irph/ijece/ijecev5n2_06.pdf
2. https://www.diva-portal.org/smash/get/diva2:1456739/FULLTEXT01.pdf
3. https://www.ijert.org/research/performance-analysis-of-adaptive-filtering-algorithms-for-acoustic-echo-cancellation-IJERTV7IS080056.pdf
4. https://abrarhashmi.files.wordpress.com/2016/02/behrouz-farhang-boroujeny-adaptive-filters_-theory-and-applications-wiley-2013.pdf



























