
Arm Neon was introduced to improve multimedia encoding/decoding, UI, graphics and gaming related features running on mobile devices. Over the years, it has been used to accelerate signal processing algorithms and functions, to speed up not only the multimedia audio and video applications but foray into deep learning and AI related applications such as voice recognition, facial recognition and computer vision. Neon Architecture provides flexibility, support for various data types and is open-sourced, one of the key reasons that applications are able to capitalize on these features.
This blog is presented as a guide with practical points about the Arm Neon architecture that every software developer can use.
Arm Neon Architecture across versions
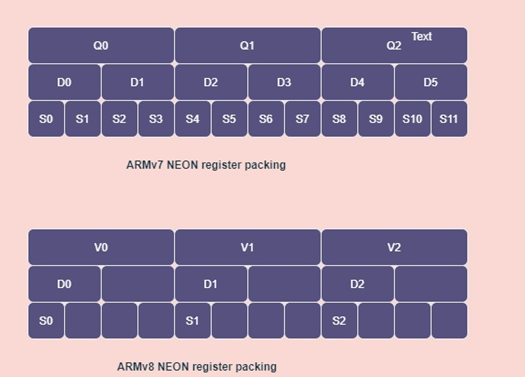
Even though the concept of the Neon is the same across multiple versions, there is a difference in how it is implemented. The major differences between Neon architecture in the Armv7 (32bit) and Armv8 (64bit) are as follows:
- In Armv7, there are Q0-Q15, 128-bit registers, which are also accessible as D0-D31 64-bit registers or S0-S31 32-bit registers. Where as in the case of Armv8 there are 32X128-bit registers, which are named as V0 to V31. But there is no longer D0-D63. There is only D0 to D31 and S0 to S31. This is because the double word or VFP registers are placed in the lower part of the quad word V0-V31 registers. So, while instructions operate on the lower half, they automatically zero the upper part of the V register.
- Since the arrangement of the registers is changed in Armv8, there are changes in the permutation instructions (reordering data, such as zip, unzip or transpose), which work differently. The permutation instruction works in-place in Armv7, but in Armv8 they require a target register.
- Because of the above-mentioned architecture changes, the Armv8 assembly codes are not backward compatible. Developers need to reanalyze, often resulting in an entirely different solution.
Arm Neon Development Support
Arm and its community provide different possibilities for a developer to make use of the Neon technologies:
- Auto-vectorization feature by compiler: Arm compilers have the capability to generate the optimized SIMD code to take advantage of Neon. In case of design time and cost, this feature is an advantage for the developer. But, in case of complex algorithms the compiler generated code won’t be optimized enough. In such cases developers have to look through intrinsics of hand tuned assemblies. The auto-vectorization includes:
Loop vectorization: unrolling loops to reduce the number of iterations, while performing more operations in each iteration.
Superword-Level Parallelism (SLP) vectorization: bundling scalar operations together to make use of full width Advanced SIMD instructions. In Armv8 architecture, Neon is enabled by default, the developer can specify Neon-capable target to target Armv8 AArch64 or specify cpu in Cortex‑A53 in AArch32 state.

In Armv7 architecture, Neon is optional. Developers can enable the Neon module using the compiler options such as -mcpu, -march and -mfpu . And auto-vectorization is enabled by default at higher optimization levels ( -O2 and higher). And -fno-vectorize settings help to disable auto-vectorization. At optimization level -O1, auto-vectorization is disabled by default. -fvectorize option lets you enable auto-vectorization. At optimization level -O0, auto-vectorization is always disabled. If you specify the -fvectorize option, the compiler ignores it.
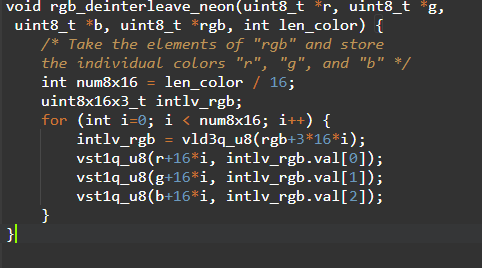
- Neon intrinsics: Neon intrinsics enables a mechanism for the developer to implement better optimized codes for the Neon architecture than the compiler generated ones, which will be an advantage to the developer, since he knows the application better than the compiler. You can refer to the arm_neon.h header file for the Neon intrinsics that are a set of C and C++ functions supported by the Arm compilers and GCC. These intrinsics accelerate development by providing similar freedom as the Neon assembly instruction and the compiler takes care of the allocation of registers. At the compilation stage, Neon intrinsics are replaced by appropriate Neon instruction or sequence of Neon instructions. An example for Neon intrinsics is as follows:
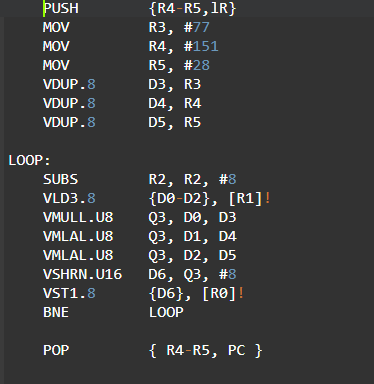
- Hand-coded Neon assembler: As an experienced program developer, you can make use of assembly instructions, to generate better optimized codes when the performance is critical. In some regions of the algorithm, you can use both Arm and Neon instructions in parallel for independent operations. A Neon assembly program looks like:
- Neon-enabled libraries: Arm and its community offers open-source libraries that already utilize Neon and developers can directly plug these libraries in their development environment. Few such libraries are:
- Arm Compute Library: This Library is a collection of low-level functions optimized for Arm CPU and GPU architectures targeted at image processing, computer vision, and machine learning.
- Ne10: Open-source C library, hosted on GitHub by Arm, are common processing intensive functions heavily optimized for Arm. Ne10 is a modular structure consisting of several smaller libraries.
- Libyuv: Open-source project that includes YUV scaling and conversion functionality.
- Skia: Open-source 2D graphics library used as the graphics engine for web browsers and operating systems.
Arm vs Neon performance improvements
From various examples, developers have proved that it is possible to achieve very good optimization in performance using the Neon SIMD instruction set. But the level of optimization achieved purely depends on your code, how much vectorization is possible. Eg. In cases of IIR filters there is a dependency of previously calculated output samples, in such cases Neon won’t be able to provide the amount of improvement compared to filters like FIR, where pure vectorization can be applied.
The following examples detail the level of optimization that can be achieved with Neon instructions, when compared to Arm instructions:
- In complex video codec (mpeg4) processing, Neon provides 1.6 – 2.5 times performance boost over Arm11.
- In Audio processing (AAC, voice recognition algorithms) FFT, Neon provides (3.8 us) 4 times performance boost over Arm11(15.2us).
- In the ffmpeg FFT, Neon provides a 12 times performance boost over Arm11
Following example demonstrates the performance improvement that can be achieved by Neon. Let us consider, simple array multiply and accumulate program ( c[i] = c[i]+ a[i] * b[i] )
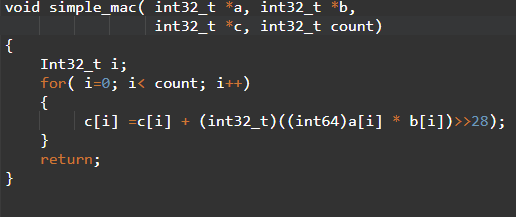
The handwritten Arm11 assembly code for the above C program is given below:
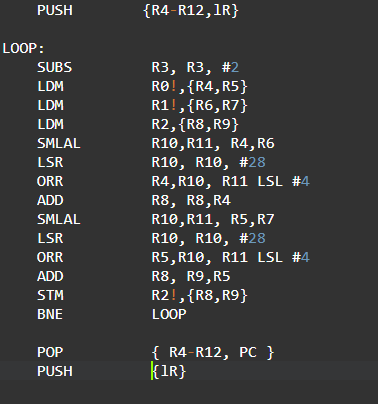
The handwritten Neon assembly code for the above C program is given below:
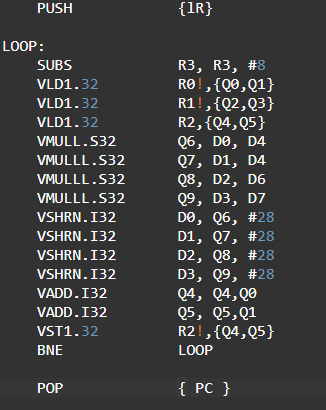
Now let us calculate the cycles for both Arm and Neon codes, considering loop count is 256:
| Operation | Arm assembly (cycles ) | Neon SIMD (cycles) |
| Load and store | (256/2)*(2+2+2+2)=1024 | (256/8)*(2+2+2+2)=256 |
| Multiply and Accumulate | (256/2)*(3+1+1+1+3+1+1+1)= 1536 | (256/8)*(2+1+1+2+1+1)=256 |
| Branch operations | (255/2)*1+4=131 | (255/8 )*1+4=35 |
| Total | 2691 | 547 |
This example shows Neon can improve the performance of your program more that 70% compared to Arm assembly code.
The Ignitarium Advantage
Ignitarium has been working on delivering core audio and video multimedia solutions to its customers. Engineers make use of the Neon optimizations for audio and video use cases.
Over the years, we have built expertise on Arm Neon intrinsics and hand tuned assemblies for Armv7 and Armv8 architectures. The team has extensively used Neon while implementing DSP Algorithms such as DCT, FFT, FIR filters, array processing and limiter for the audio use cases.




























Comments are closed.