
Abstract
The need for Automatic Speech Command Recognition (ASCR / ASR) on IoT devices is gaining traction because of the increased interest in non-touch-based applications. This article introduces a new lightweight convolutional neural network (CNN) for ASR on microcontrollers. The proposed model is comparable to current state-of-the-art networks with a very low parameter count of less than 63k. The new model gives an accuracy of 96.13% on the Google Speech Commands V2 dataset. A comparative study of results on previous models on the same dataset is also presented.
1. Introduction
Currently, ASR is being done using human-computer interfaces like Google speech, Siri, Alexa which require a client-server mode for its operation as the neural network is very computationally expensive. So, for devices with no internet access, doing speech recognition becomes a non-viable option, as the device itself cannot run very computationally expensive networks. In this paper, we present a very lightweight neural network suitable for low-power devices like microcontrollers.
The network should satisfy the following constraints to run on microcontrollers:
- Memory Footprint: Very small memory footprint, ranging in the few 10s of KiloBytes
- Low Compute Power: Limited MCPS processor cores in the range of a few 10s of MHz to sub-200MHz.
- Offline: All processing should be done locally without cloud connectivity
The remaining contents of this paper are organized in the following sections: 2: Model Architecture, 3: Training Methodology, and 4: Results.
2. Model Architecture
The model is composed using Keras with a Tensorflow backend. An audio file consists of a single word; hence, the current model can be thought of as a classification model. Each audio file is a single channel mono wav file, sampled to 16000 Hz and provided as the input to the network. 40 band Mel Frequency Cepstral Coefficients (MFCC) features are extracted from the audio sample and fed into the network. These MFCC features are fed into a custom convolutional neural network (CNN) for generating the classification results.
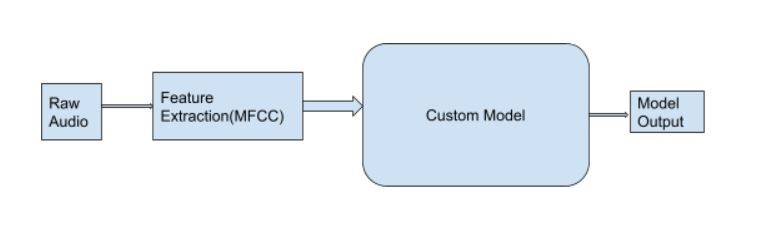
Fig 1.0 High-Level Model Architecture
3. Experimental Results
3.1 Model Integration
For all the experiments, the github repository [3] was referred. To maintain uniformity of all experiments, all aspects of the repository except for our custom model was kept the same.
3.2 Experimental Setup
For the experiment, the dataset used is the Google Speech Commands (GSC) 12 class set with the following keywords: ‘_unknown_’, ‘left’, ‘on’, ‘stop’, ‘right’, ‘off’, ‘down’, ‘up’, ‘no’, ‘go’, ‘yes’, ‘_silence_’ [1]. All keywords are sampled at 16kHz and are of duration 1s.
The GSC V2 comprises 36 folders with the dataset split into train, validation, and test based on predefined percentages. 10% of the total dataset is split as a test and 10% as validation, the remaining 80% is categorized as train data. The keywords not belonging to the above-mentioned keyword list are classified as unknowns. The composition of the train and test set is as shown in the table below.
| Class | Counts | Class | Counts | |
| on | 3086 | on | 396 | |
| right | 3019 | right | 396 | |
| stop | 3111 | stop | 411 | |
| up | 2948 | up | 425 | |
| down | 3134 | down | 406 | |
| no | 3130 | no | 405 | |
| go | 3106 | go | 402 | |
| left | 3037 | left | 412 | |
| yes | 3228 | yes | 419 | |
| off | 2970 | off | 402 | |
| unknown | 6154 | unknown | 816 | |
| silence | 3077 | silence | 408 |
Table 1.0: a) train data counts per class b) test data counts per class
The background noise class present in the Google Speech Commands dataset is not considered for training as a class, but it is mixed with other speech signals to create augmented data. Silence class is generated by multiplying a random file with zeros and the count of silence class is calculated as 10% of total files in any random folder. All metrics and methods are in accordance with standard practices [1,2]. The table below is generated with reference from [1].
| Model | Accuracy | Model Size (Kbits) |
| DNN | 90.6 | 3576 |
| CNN+strd | 95.6 | 4232 |
| CNN | 96.0 | 4848 |
| GRU(S) | 96.3 | 4744 |
| CRNN(S) | 96.5 | 3736 |
| SVDF | 96.9 | 2832 |
| DSCNN | 96.9 | 3920 |
| TinySpeech-A | 94.3 | 127 |
| TinySpeech-B | 91.3 | 53 |
| LMU1 | 96.9 | 1683 |
| LMU2 | 95.9 | 361 |
| LMU3 | 95.0 | 105 |
| LMU4 | 92.7 | 49 |
| IGN-CNN(our model) | 96.13 | 490 |
Table 2.0 Accuracy Results for different networks, based on GSC V2 dataset
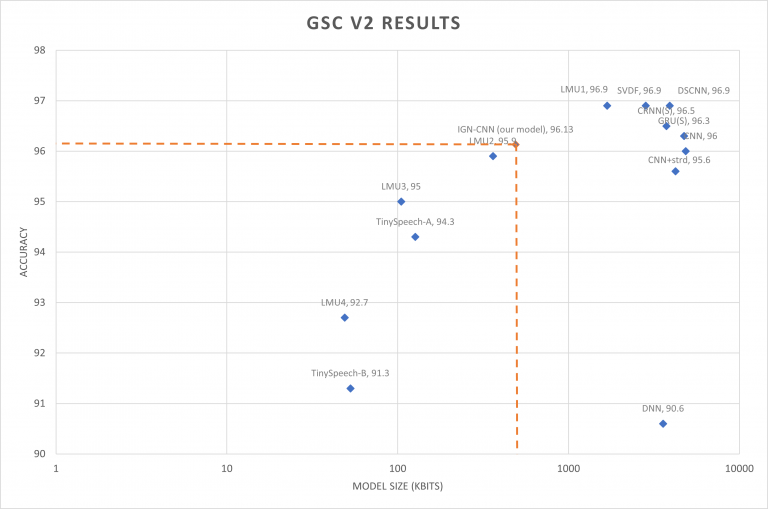
Fig 2.0 Scatterplot comparison of various networks: Accuracy vs Model size
4. Conclusion
A new, lightweight CNN-based model for ASR, optimized for embedded microcontroller devices, was developed. We have benchmarked the model against comparable models using the Google Speech Commands V2 dataset. The accuracy results and total model footprint are comparable to the prevalent state-of-the-art models. This model architecture has been deployed on multiple variants of low-cost microcontrollers from leading semiconductor manufacturers
5. References
- Peter Blouw, Gurshaant Malik, Benjamin Morcos, Aaron R. Voelker, and Chris Eliasmith “Hardware Aware Training for Efficient Keyword Spotting on General Purpose and Specialized Hardware”, https://arxiv.org/pdf/2009.04465.pdf
- Oleg Rybakov, Natasha Kononenko, Niranjan Subrahmanya, Mirko Visontai, Stella Laurenzo, “Streaming keyword spotting on mobile devices”, https://arxiv.org/pdf/2005.06720.pdf
- Reference code, https://github.com/google-research/google-research/tree/master/kws_streaming


























1 thought on “A new lightweight CNN model for Automatic Speech Command Recognition on Microcontrollers”
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.