
Despite the ubiquitous presence of voice assistants in our homes and workplaces, the technological intricacies of how automatic speech recognition works continue to amaze us.
One of the most crucial aspects that determines the accuracy of a good voice assistant is based on testing it in generalized real-world environments, which unfortunately is very difficult to do. Hence, engineers implement the test infrastructure to simulate these environments. In this blog, we will see how the Audio AI team at Ignitarium tests its deep learning models on real-world simulations.
Dataset Preparation and Collection
A real-world audio signal is very challenging to create in a simulated environment. In order to do so, two sets of audio are needed namely: noisy signals (background noise) and specific audio keywords of interest (KOI).
Noisy signals are collected in different formats from thousands of sources like work locations, industrial shop floors, bus stations, birds chirping, computer-generated noises, etc.
KOIs are collected through Ignitarium’s cloud-based data collection component, AudioFarm, which is part of our comprehensive SeptraTM Audio ML platform. Once the two sets of audios are collected, they are made into a common format (“.wav”) at a fixed sampling rate of 16 KHz as it aids in different data manipulation operations.
Data Labeling
Data Labeling is an important part of any machine learning model. A good model requires quality data, which in turn requires meticulous labelling especially in the case of audio. To ensure the quality of real-world simulated audio, which for simplicity we will be calling as ‘long audio’, our KOIs need to be properly labelled. The KOIs collected usually have a lot of unwanted noise, so the audio files need to be listened to and the starting and endpoints of the speech region marked. These points are then saved as json files, which in turn are referenced, during long audio generation.

Fig 1 Audio Labeling Tool
Long Audio Creation
For creating a long audio file, a random noise sample is picked and a 10 second duration clip is cropped. Or if the noise sample has duration less than 10 seconds, it is repeated to meet the criteria. The 10s noise sample is randomly set to a minimum loudness value and maximum loudness value (in dB) in a config file.
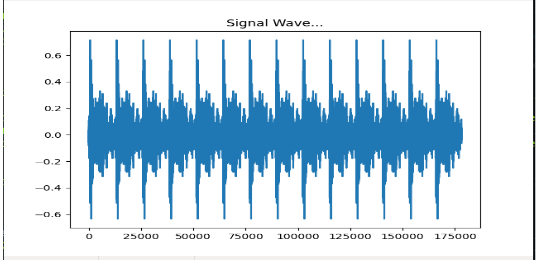
Fig. 2: Random Noise Sample
Next, a random KOI is selected based on a set of preconditions. The preconditions are kept in a configuration file for ease of accessibility. The preconditions include minimum and maximum sample duration and loudness, maximum allowable signal to noise ratio (SNR) etc. Based on these conditions, the KOI is embedded randomly anywhere within the noise signal respecting the max allowable SNR and max allowable noise dB.
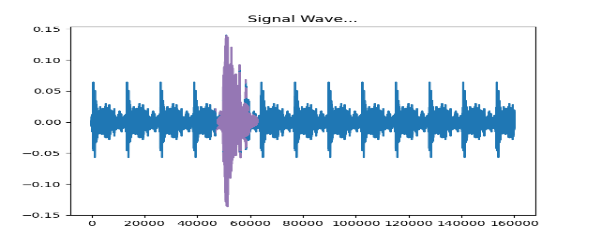
Fig. 3: KOI embedded noise signal
The next KOI will be embedded by maintaining a random distance between minimum allowable duration and maximum allowable duration. Special attention is also given to ensure that the noise clips don’t get attenuated because of speech embedding. These steps are repeated till it becomes impossible to further insert a KOI into the long audio.
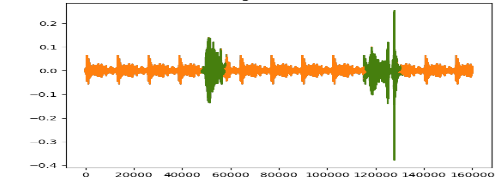
Fig. 4: Multiple KOI embedded noise
The above steps are repeated multiple times to generate long audio of any desired length. Along with the generated long audio wav file, a metadata file and a csv is also created. The metadata will capture the properties of the contents of the long audio file. The csv file contains the start end location of KOI(s) in the long audio.
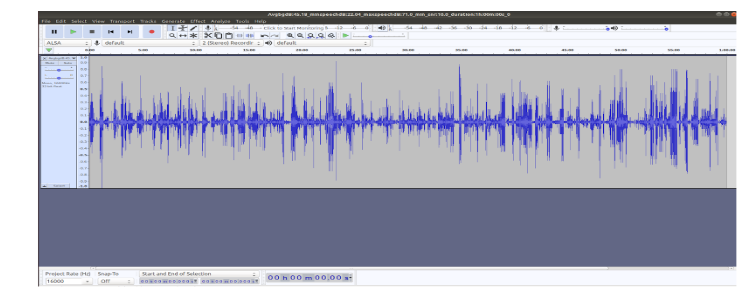
Fig. 5: Final generated long audio
Conclusion
Validating the accuracy of voice command engines against real-world conditions is a complicated task, requiring significant time and resources. In this article, we show how representative audio is created in a fully configurable and automated manner, allowing our Audio ML engineering teams to have confidence in our model accuracy very early in their development cycles.
In a follow-on article, we’ll be describing how the generated ‘long audio’ is integrated into our automated audio test framework in Ignitarium’s ‘Sound Lab’. This allows playback and accuracy testing of our voice engines running on physical embedded boards.


























237 thoughts on “Simulating Real World Audio for Voice Command Engine”
Your article helped me a lot, is there any more related content? Thanks! https://accounts.binance.com/pt-PT/register?ref=DB40ITMB
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
IverCare Pharmacy: ivermectin 1.87 dosage for cats – liquid ivermectin for humans
Online betting Philippines: Online betting Philippines – Jollibet online sabong
maglaro ng Jiliko online sa Pilipinas: Jiliko – Jiliko app
https://gkwinviet.company/# Dang ky GK88
Online casino Jollibet Philippines: Jollibet online sabong – jollibet login
Jiliko casino walang deposit bonus para sa Pinoy [url=https://jilwin.pro/#]Jiliko bonus[/url] Jiliko login
Abutogel: Jackpot togel hari ini – Abutogel login
Jiliko: Jiliko casino walang deposit bonus para sa Pinoy – Jiliko login
Rút ti?n nhanh GK88: Trò choi n? hu GK88 – Casino online GK88
Swerte99 online gaming Pilipinas: Swerte99 casino – Swerte99 login
Swerte99 online gaming Pilipinas [url=https://swertewin.life/#]Swerte99 bonus[/url] Swerte99 online gaming Pilipinas
Slot gacor Beta138: Beta138 – Situs judi resmi berlisensi
Onlayn kazino Az?rbaycan: Onlayn rulet v? blackjack – Yüks?k RTP slotlar
https://jilwin.pro/# Jiliko casino
Jiliko bonus: maglaro ng Jiliko online sa Pilipinas – Jiliko login
Abutogel login: Abutogel login – Bandar togel resmi Indonesia
Jackpot togel hari ini [url=https://abutowin.icu/#]Bandar togel resmi Indonesia[/url] Abutogel login
Link alternatif Mandiribet: Slot jackpot terbesar Indonesia – Judi online deposit pulsa
Situs judi resmi berlisensi: Promo slot gacor hari ini – Bonus new member 100% Beta138
Swerte99: Swerte99 slots – Swerte99 login
Situs judi resmi berlisensi: Promo slot gacor hari ini – Beta138
https://t.me/s/Official_1win_kanal/1020
Link alternatif Mandiribet [url=https://mandiwinindo.site/#]Live casino Mandiribet[/url] Link alternatif Mandiribet
Swerte99 casino: Swerte99 login – Swerte99
https://mandiwinindo.site/# Bonus new member 100% Mandiribet
Jiliko casino walang deposit bonus para sa Pinoy: Jiliko casino – Jiliko login
Bonus new member 100% Beta138: Beta138 – Bandar bola resmi
Live casino Indonesia [url=https://betawinindo.top/#]Slot gacor Beta138[/url] Link alternatif Beta138
Situs judi resmi berlisensi: Withdraw cepat Beta138 – Live casino Indonesia
https://t.me/s/Webs_1WIN
Swerte99 login: Swerte99 slots – Swerte99 login
1winphili: Online betting Philippines – Online betting Philippines
Online betting Philippines: Online betting Philippines – jollibet login
Swerte99 online gaming Pilipinas [url=https://swertewin.life/#]Swerte99 casino[/url] Swerte99 app
Qeydiyyat bonusu Pinco casino: Canli krupyerl? oyunlar – Pinco il? real pul qazan
Swerte99 online gaming Pilipinas: Swerte99 – Swerte99 casino walang deposit bonus para sa Pinoy
https://mandiwinindo.site/# Mandiribet
Judi online deposit pulsa: Situs judi resmi berlisensi – Situs judi online terpercaya Indonesia
Online casino Jollibet Philippines [url=https://1winphili.company/#]jollibet app[/url] jollibet
jollibet casino: jollibet login – 1winphili
Bandar bola resmi: Login Beta138 – Link alternatif Beta138
Link alternatif Beta138: Bonus new member 100% Beta138 – Slot gacor Beta138
Yüks?k RTP slotlar: Pinco r?smi sayt – Qeydiyyat bonusu Pinco casino
Tro choi n? hu GK88 [url=https://gkwinviet.company/#]Tro choi n? hu GK88[/url] Khuy?n mai GK88
Rut ti?n nhanh GK88: GK88 – Nha cai uy tin Vi?t Nam
https://pinwinaz.pro/# Onlayn kazino Az?rbaycan
Nha cai uy tin Vi?t Nam: GK88 – Rut ti?n nhanh GK88
Pinco il? real pul qazan: Pinco casino mobil t?tbiq – Qeydiyyat bonusu Pinco casino
1winphili [url=https://1winphili.company/#]Online betting Philippines[/url] jollibet app
Jiliko login: Jiliko login – maglaro ng Jiliko online sa Pilipinas
Casino online GK88: Casino online GK88 – Ca cu?c tr?c tuy?n GK88
Официальный Telegram канал 1win Casinо. Казинo и ставки от 1вин. Фриспины, актуальное зеркало официального сайта 1 win. Регистрируйся в ван вин, соверши вход в один вин, получай бонус используя промокод и начните играть на реальные деньги.
https://t.me/s/Official_1win_kanal/4861
MediDirect USA: southern pharmacy – MediDirect USA
Indian Meds One: Indian Meds One – Indian Meds One
cheap cialis mexico: Mexican Pharmacy Hub – order azithromycin mexico
Indian Meds One [url=http://indianmedsone.com/#]п»їlegitimate online pharmacies india[/url] reputable indian online pharmacy
https://indianmedsone.shop/# Indian Meds One
pharmacies in mexico that ship to usa: Mexican Pharmacy Hub – Mexican Pharmacy Hub
banfield online pharmacy: online cialis pharmacy reviews – MediDirect USA
MediDirect USA: MediDirect USA – rite aid pharmacy viagra prices
lexapro pharmacy assistance [url=http://medidirectusa.com/#]MediDirect USA[/url] generic zoloft online pharmacy no prescription
sildenafil mexico online: Mexican Pharmacy Hub – Mexican Pharmacy Hub
MediDirect USA: MediDirect USA – MediDirect USA
Mexican Pharmacy Hub: modafinil mexico online – Mexican Pharmacy Hub
https://mexicanpharmacyhub.shop/# Mexican Pharmacy Hub
Indian Meds One: india online pharmacy – top 10 pharmacies in india
MediDirect USA: cytotec in malaysia pharmacy – MediDirect USA
Mexican Pharmacy Hub [url=http://mexicanpharmacyhub.com/#]legit mexico pharmacy shipping to USA[/url] semaglutide mexico price
flomax pharmacy: MediDirect USA – MediDirect USA
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Indian Meds One: buy medicines online in india – indianpharmacy com
Indian Meds One: legitimate online pharmacies india – Indian Meds One
https://indianmedsone.shop/# Indian Meds One
singapore pharmacy online store: kamagra oral jelly – MediDirect USA
MediDirect USA [url=https://medidirectusa.com/#]MediDirect USA[/url] MediDirect USA
Indian Meds One: online shopping pharmacy india – indian pharmacy paypal
MediDirect USA: online pharmacy review – MediDirect USA
mexican pharmacy for americans: Mexican Pharmacy Hub – Mexican Pharmacy Hub
Mexican Pharmacy Hub [url=https://mexicanpharmacyhub.com/#]Mexican Pharmacy Hub[/url] tadalafil mexico pharmacy
Zithromax: warfarin testing pharmacy – MediDirect USA
buying prescription drugs in mexico: reputable mexican pharmacies online – medication from mexico pharmacy
legit mexican pharmacy without prescription: Mexican Pharmacy Hub – order azithromycin mexico
https://medidirectusa.shop/# pharmacy clothing store
tetracycline pharmacy: MediDirect USA – MediDirect USA
MediDirect USA [url=https://medidirectusa.com/#]mexican online pharmacy percocet[/url] MediDirect USA
Online medicine home delivery: reputable indian pharmacies – top 10 pharmacies in india
Mexican Pharmacy Hub: Mexican Pharmacy Hub – buy neurontin in mexico
Mexican Pharmacy Hub: online mexico pharmacy USA – order kamagra from mexican pharmacy
Indian Meds One: buy medicines online in india – Indian Meds One
best indian pharmacy online: ohio pharmacy law adipex – ed medication
https://medidirectusa.com/# MediDirect USA
MediDirect USA: pharmacy selling viagra – pharmacy lexapro vs celexa
top 10 pharmacies in india: indian pharmacy paypal – pharmacy website india
Mexican Pharmacy Hub: Mexican Pharmacy Hub – Mexican Pharmacy Hub
MediDirect USA: MediDirect USA – pharmacy propecia
Safe access to generic ED medication [url=http://kamameds.com/#]Sildenafil oral jelly fast absorption effect[/url] KamaMeds
where can i buy sildenafil tablets: SildenaPeak – viagra for women online
Sildenafil oral jelly fast absorption effect: Affordable sildenafil citrate tablets for men – KamaMeds
Kamagra oral jelly USA availability: Men’s sexual health solutions online – Kamagra reviews from US customers
https://kamameds.com/# Kamagra reviews from US customers
sildenafil best price canada [url=https://sildenapeak.shop/#]can you order viagra online in canada[/url] best sildenafil
Affordable sildenafil citrate tablets for men: Kamagra oral jelly USA availability – Men’s sexual health solutions online
maxim peptide tadalafil citrate: Tadalify – Tadalify
Tadalify: buying cialis internet – free samples of cialis
SildenaPeak: cheapest sildenafil 100mg uk – women viagra price
SildenaPeak: viagra online hong kong – SildenaPeak
cipla tadalafil review [url=https://tadalify.shop/#]Tadalify[/url] whats the max safe dose of tadalafil xtenda for a healthy man
https://sildenapeak.shop/# order viagra online uk
SildenaPeak: SildenaPeak – SildenaPeak
SildenaPeak: SildenaPeak – SildenaPeak
SildenaPeak: SildenaPeak – SildenaPeak
Tadalify: cialis online canada ripoff – cialis patent expiration 2016
KamaMeds: Fast-acting ED solution with discreet packaging – Kamagra reviews from US customers
ED treatment without doctor visits: Online sources for Kamagra in the United States – ED treatment without doctor visits
Tadalify [url=http://tadalify.com/#]Tadalify[/url] Tadalify
https://sildenapeak.shop/# SildenaPeak
Compare Kamagra with branded alternatives: Affordable sildenafil citrate tablets for men – Kamagra reviews from US customers
Tadalify: where can i buy cialis on line – canadian online pharmacy cialis
Sildenafil oral jelly fast absorption effect: Online sources for Kamagra in the United States – ED treatment without doctor visits
cialis manufacturer coupon [url=https://tadalify.shop/#]Tadalify[/url] Tadalify
Tadalify: Tadalify – cialis 20 mg how long does it take to work
Fast-acting ED solution with discreet packaging: Affordable sildenafil citrate tablets for men – ED treatment without doctor visits
SildenaPeak: SildenaPeak – SildenaPeak
https://sildenapeak.shop/# viagra tablets over the counter
Non-prescription ED tablets discreetly shipped: ED treatment without doctor visits – ED treatment without doctor visits
can i order viagra [url=https://sildenapeak.shop/#]SildenaPeak[/url] SildenaPeak
generic viagra us pharmacy: price of sildenafil 50 mg – SildenaPeak
1 viagra: where can i buy viagra canada – sildenafil 80 mg
SildenaPeak: viagra 100 mg price in india – SildenaPeak
Tadalify [url=http://tadalify.com/#]Tadalify[/url] Tadalify
KamaMeds: Affordable sildenafil citrate tablets for men – Fast-acting ED solution with discreet packaging
viagra generic online cheapest: SildenaPeak – SildenaPeak
http://tadalify.com/# Tadalify
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
KamaMeds: Online sources for Kamagra in the United States – ED treatment without doctor visits
generic tadalafil tablet or pill photo or shape: Tadalify – cialis 100 mg usa
SildenaPeak: generic female viagra in india – SildenaPeak
Kamagra reviews from US customers [url=https://kamameds.com/#]KamaMeds[/url] Kamagra oral jelly USA availability
Tadalify: Tadalify – cialis effectiveness
viagra for sale online in canada: generic viagra 100mg price in india – cheapest brand name viagra
buy viagra via paypal: SildenaPeak – SildenaPeak
https://kamameds.com/# Affordable sildenafil citrate tablets for men
viagra online using paypal: SildenaPeak – SildenaPeak
Tadalify: tadalafil long term usage – Tadalify
Kamagra oral jelly USA availability: Kamagra reviews from US customers – ED treatment without doctor visits
purchase viagra online cheap: viagra south africa price – get viagra prescription online
Tadalify [url=https://tadalify.shop/#]when does cialis patent expire[/url] Tadalify
Tadalify: Tadalify – Tadalify
Compare Kamagra with branded alternatives: ED treatment without doctor visits – KamaMeds
https://kamameds.shop/# Fast-acting ED solution with discreet packaging
Tadalify: cialis super active real online store – how to buy cialis
Tadalify [url=http://tadalify.com/#]printable cialis coupon[/url] Tadalify
generic viagra sildenafil: australia generic viagra – SildenaPeak
does tadalafil work: Tadalify – Tadalify
SildenaPeak: buy viagra cheap australia – generic viagra us
Online sources for Kamagra in the United States [url=https://kamameds.shop/#]KamaMeds[/url] Safe access to generic ED medication
cialis super active: 20 mg tadalafil best price – tadacip tadalafil
Tadalify: Tadalify – super cialis
https://tadalify.shop/# walgreen cialis price
Fast-acting ED solution with discreet packaging: Kamagra reviews from US customers – Compare Kamagra with branded alternatives
sildenafil generic mexico: SildenaPeak – viagra without rx
where to get viagra over the counter: 711 viagra pills – generic viagra sales
Non-prescription ED tablets discreetly shipped [url=http://kamameds.com/#]Sildenafil oral jelly fast absorption effect[/url] Affordable sildenafil citrate tablets for men
SildenaPeak: SildenaPeak – SildenaPeak
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Tadalify: Tadalify – Tadalify
http://kamameds.com/# Safe access to generic ED medication
purchase cialis: Tadalify – Tadalify
ivermectin horse: ivermectin at tractor supply – IverGrove
SteroidCare Pharmacy [url=https://steroidcarepharmacy.com/#]SteroidCare Pharmacy[/url] SteroidCare Pharmacy
FertiCare Online: can i get clomid prices – order clomid pills
how to get cheap clomid pills: where can i get clomid without rx – FertiCare Online
prednisone 5mg daily: prednisone generic cost – canada pharmacy prednisone
FertiCare Online [url=https://ferticareonline.shop/#]FertiCare Online[/url] cost cheap clomid without prescription
horse ivermectin for dogs: ivermectin 3 mg para que sirve – ivermectin 200mg
amoxicillin in india: can i purchase amoxicillin online – amoxicillin buy canada
where can i get clomid prices: can i order generic clomid tablets – order generic clomid prices
FertiCare Online: order clomid prices – can i purchase clomid no prescription
ivermectin injections: IverGrove – ivermectin purchase
TrustedMeds Direct: amoxicillin generic – TrustedMeds Direct
FertiCare Online: FertiCare Online – can i order clomid without prescription
IverGrove: ivermectin apple paste – IverGrove
https://ferticareonline.shop/# can you get generic clomid online
FertiCare Online: FertiCare Online – FertiCare Online
ivermectin generic: IverGrove – topical ivermectin
IverGrove: IverGrove – IverGrove
CardioMeds Express: furosemide 40 mg – CardioMeds Express
furosemide 100 mg: CardioMeds Express – lasix furosemide 40 mg
prednisone 20mg tab price: SteroidCare Pharmacy – SteroidCare Pharmacy
https://ivergrove.com/# ivermectin for cattle
SteroidCare Pharmacy [url=https://steroidcarepharmacy.com/#]prednisone cost 10mg[/url] prednisone online paypal
where to get generic clomid online: FertiCare Online – FertiCare Online
CardioMeds Express: CardioMeds Express – lasix 100 mg
cost of generic clomid no prescription [url=http://ferticareonline.com/#]FertiCare Online[/url] order cheap clomid
prednisone 5 mg tablet without a prescription: prednisone tablet 100 mg – SteroidCare Pharmacy
Farmacie online sicure: medicinali senza prescrizione medica – farmacie online affidabili
viagra subito: viagra generico a basso costo – viagra prezzo farmacia 2023
acquisto farmaci con ricetta [url=https://forzaintima.com/#]consegna rapida e riservata kamagra[/url] farmacia online piГ№ conveniente
farmacia online: acquistare cialis generico online – acquistare farmaci senza ricetta
top farmacia online: kamagra originale e generico online – farmaci senza ricetta elenco
farmacie online autorizzate elenco: cialis online Italia – Farmacia online migliore
https://pillolesubito.shop/# farmacie online affidabili
Farmacie on line spedizione gratuita [url=https://forzaintima.com/#]sildenafil generico senza ricetta[/url] farmacie online affidabili
farmacie online sicure: consegna rapida in tutta Italia – farmacia online piГ№ conveniente
Farmacia online piГ№ conveniente: farmacie online affidabili – migliori farmacie online 2024
farmacia online: cialis online Italia – migliori farmacie online 2024
acquisto farmaci con ricetta [url=http://pillolesubito.com/#]acquisto discreto di medicinali in Italia[/url] Farmacie online sicure
farmacie online affidabili: Farmaci Diretti – farmacie online affidabili
http://potenzafacile.com/# alternativa al viagra senza ricetta in farmacia
top farmacia online: medicinali senza prescrizione medica – comprare farmaci online con ricetta
comprare farmaci online con ricetta: farmaci generici a prezzi convenienti – farmacie online autorizzate elenco
le migliori pillole per l’erezione [url=https://potenzafacile.com/#]PotenzaFacile[/url] viagra generico sandoz
farmacia online piГ№ conveniente: soluzioni rapide per la potenza maschile – acquisto farmaci con ricetta
Farmacia online miglior prezzo: kamagra originale e generico online – Farmacie on line spedizione gratuita
acquisto farmaci con ricetta: Forza Intima – п»їFarmacia online migliore
MapleMeds Direct: doxycycline generics pharmacy – MapleMeds Direct
BharatMeds Direct: BharatMeds Direct – BharatMeds Direct
MapleMeds Direct: meds online without doctor prescription – indomethacin capsules pharmacy
MapleMeds Direct [url=https://maplemedsdirect.com/#]MapleMeds Direct[/url] cephalexin pharmacy
BorderMeds Express: generic drugs mexican pharmacy – BorderMeds Express
https://bharatmedsdirect.com/# BharatMeds Direct
MapleMeds Direct: is rx pharmacy coupons legit – MapleMeds Direct
mexican drugstore online: BorderMeds Express – BorderMeds Express
order kamagra from mexican pharmacy [url=http://bordermedsexpress.com/#]BorderMeds Express[/url] BorderMeds Express
BharatMeds Direct: BharatMeds Direct – buy medicines online in india
finasteride mexico pharmacy: best prices on finasteride in mexico – BorderMeds Express
india pharmacy mail order: BharatMeds Direct – indianpharmacy com
buy propecia mexico [url=https://bordermedsexpress.com/#]best mexican pharmacy online[/url] buy from mexico pharmacy
https://bordermedsexpress.com/# mexican mail order pharmacies
BharatMeds Direct: BharatMeds Direct – indian pharmacies safe
BharatMeds Direct: pharmacy website india – BharatMeds Direct
MapleMeds Direct: MapleMeds Direct – viagra pharmacy australia
BharatMeds Direct [url=https://bharatmedsdirect.com/#]BharatMeds Direct[/url] BharatMeds Direct
BharatMeds Direct: BharatMeds Direct – BharatMeds Direct
MapleMeds Direct: MapleMeds Direct – Nitroglycerin