
Despite the ubiquitous presence of voice assistants in our homes and workplaces, the technological intricacies of how automatic speech recognition works continue to amaze us.
One of the most crucial aspects that determines the accuracy of a good voice assistant is based on testing it in generalized real-world environments, which unfortunately is very difficult to do. Hence, engineers implement the test infrastructure to simulate these environments. In this blog, we will see how the Audio AI team at Ignitarium tests its deep learning models on real-world simulations.
Dataset Preparation and Collection
A real-world audio signal is very challenging to create in a simulated environment. In order to do so, two sets of audio are needed namely: noisy signals (background noise) and specific audio keywords of interest (KOI).
Noisy signals are collected in different formats from thousands of sources like work locations, industrial shop floors, bus stations, birds chirping, computer-generated noises, etc.
KOIs are collected through Ignitarium’s cloud-based data collection component, AudioFarm, which is part of our comprehensive SeptraTM Audio ML platform. Once the two sets of audios are collected, they are made into a common format (“.wav”) at a fixed sampling rate of 16 KHz as it aids in different data manipulation operations.
Data Labeling
Data Labeling is an important part of any machine learning model. A good model requires quality data, which in turn requires meticulous labelling especially in the case of audio. To ensure the quality of real-world simulated audio, which for simplicity we will be calling as ‘long audio’, our KOIs need to be properly labelled. The KOIs collected usually have a lot of unwanted noise, so the audio files need to be listened to and the starting and endpoints of the speech region marked. These points are then saved as json files, which in turn are referenced, during long audio generation.

Fig 1 Audio Labeling Tool
Long Audio Creation
For creating a long audio file, a random noise sample is picked and a 10 second duration clip is cropped. Or if the noise sample has duration less than 10 seconds, it is repeated to meet the criteria. The 10s noise sample is randomly set to a minimum loudness value and maximum loudness value (in dB) in a config file.
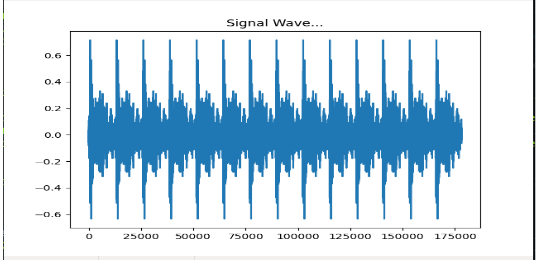
Fig. 2: Random Noise Sample
Next, a random KOI is selected based on a set of preconditions. The preconditions are kept in a configuration file for ease of accessibility. The preconditions include minimum and maximum sample duration and loudness, maximum allowable signal to noise ratio (SNR) etc. Based on these conditions, the KOI is embedded randomly anywhere within the noise signal respecting the max allowable SNR and max allowable noise dB.
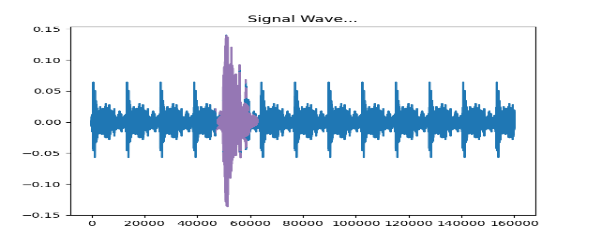
Fig. 3: KOI embedded noise signal
The next KOI will be embedded by maintaining a random distance between minimum allowable duration and maximum allowable duration. Special attention is also given to ensure that the noise clips don’t get attenuated because of speech embedding. These steps are repeated till it becomes impossible to further insert a KOI into the long audio.
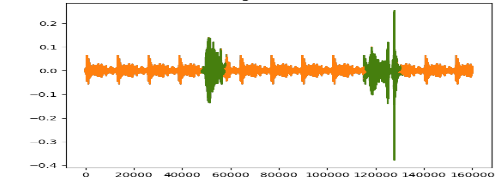
Fig. 4: Multiple KOI embedded noise
The above steps are repeated multiple times to generate long audio of any desired length. Along with the generated long audio wav file, a metadata file and a csv is also created. The metadata will capture the properties of the contents of the long audio file. The csv file contains the start end location of KOI(s) in the long audio.
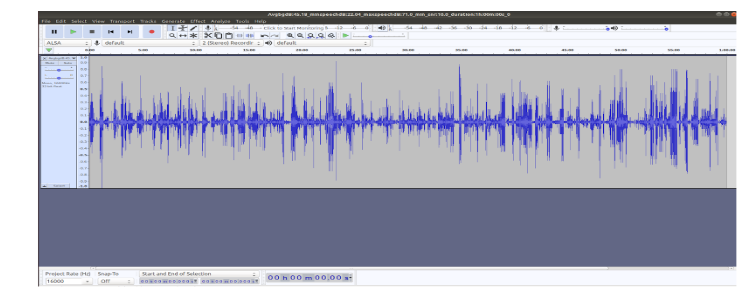
Fig. 5: Final generated long audio
Conclusion
Validating the accuracy of voice command engines against real-world conditions is a complicated task, requiring significant time and resources. In this article, we show how representative audio is created in a fully configurable and automated manner, allowing our Audio ML engineering teams to have confidence in our model accuracy very early in their development cycles.
In a follow-on article, we’ll be describing how the generated ‘long audio’ is integrated into our automated audio test framework in Ignitarium’s ‘Sound Lab’. This allows playback and accuracy testing of our voice engines running on physical embedded boards.


























2 thoughts on “Simulating Real World Audio for Voice Command Engine”
Your article helped me a lot, is there any more related content? Thanks! https://accounts.binance.com/pt-PT/register?ref=DB40ITMB
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.