
Introduction
The second part of the Visual SLAM blog series discusses one of the key components in visual SLAM: the feature extraction pipeline, which includes triangulation and map point creation. These steps play a critical role in accurately estimating the robot’s pose and creating a map of the surrounding environment. In this blog, we will delve into the fundamental concepts of triangulation and map point creation, their significance in visual SLAM, and various algorithms used to achieve robust localization and mapping.
For a better understanding of this topic, check out the first part of this series that provides a comprehensive study of different components of feature based visual SLAM algorithms, including their underlying principles.
1. Understanding Triangulation
Triangulation is a geometric process used in visual SLAM to estimate the 3D position of a feature point in the world based on its projections in two or more camera views. The underlying principle behind triangulation is to find the intersection of rays originating from the camera centers and passing through the image points. By computing the 3D position of these map points, the visual SLAM system can create a sparse 3D map of the environment.
1.1 Epipolar Geometry
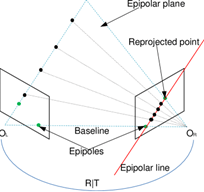
Before diving into the details of triangulation, it is essential to grasp the concept of epipolar geometry. Epipolar geometry defines the relationship between corresponding points in two camera images and plays a crucial role in feature matching and triangulation. The epipolar geometry is defined by the epipolar line, which represents the possible positions of a corresponding point in the other image.
In a stereo vision system with two cameras, denoted as O_L and O_R, along with their respective image planes, a key property is observed: the camera centers, a 3D point, and its re-projections onto the images all lie in a common plane. When an image point is backprojected, it corresponds to a ray in 3D space. This ray, when projected back onto the second image, gives rise to a line known as the epipolar line (depicted in red in figure 1). Importantly, the 3D point lies on this ray, implying that the image of the 3D point in the second view must reside on the epipolar line.
To determine the relative pose between O_L and O_R, the essential matrix E comes into play. The essential matrix is an algebraic representation of epipolar geometry, specifically designed for situations where camera calibration is known. Utilizing the essential matrix, we can efficiently compute the relationship between the two camera centers and their relative orientation, providing valuable information for stereo vision and 3D reconstruction tasks.
1.2 Feature Matching
Feature matching is the process of finding corresponding features (also known as keypoints) between two or more camera images. Common feature detection algorithms like SIFT, SURF, ORB, and AKAZE are used to extract distinctive keypoints from the images. These keypoints are then matched using methods like brute-force matching, FLANN-based matching, or RANSAC to filter out incorrect matches and identify corresponding points.
2. Triangulation Methods
Several triangulation methods are used in visual SLAM to estimate the 3D positions of map points. Some of the popular ones include:
2.1 Direct Linear Transform (DLT) Triangulation
DLT is a straightforward triangulation method based on linear algebra. It involves solving a set of linear equations to find the 3D position of a map point from its 2D projections in multiple images. Although simple, DLT may suffer from numerical instability and is sensitive to noise and outliers.
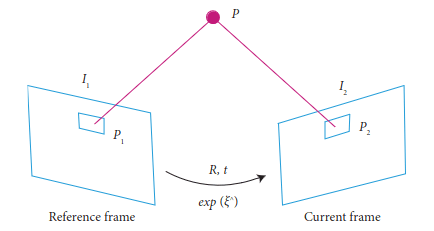
Principle of DLT:
The DLT algorithm aims to establish a correspondence between points in the 3D world space and their projections onto the 2D image plane. It leverages a set of point correspondences between the 3D points and their 2D projections in multiple images taken from different camera poses. By solving a system of linear equations, DLT estimates the camera matrix, which encapsulates both the camera’s intrinsic parameters (focal length, principal point) and extrinsic parameters (rotation and translation).
2.2 Iterative Linear Least Squares Triangulation
This method improves upon DLT by using iterative optimization techniques like Gauss-Newton or Levenberg-Marquardt to refine the 3D position estimates. By iteratively minimizing the reprojection error (the difference between the actual 2D projections and the estimated 2D projections), this approach provides more accurate and robust 3D map points.
Principle of ILS:
ILS aims to refine the estimation of 3D landmark positions based on the observed 2D image points and corresponding camera poses. Given a set of camera poses and the associated image observations, the initial triangulation can be achieved using linear methods like the Direct Linear Transform (DLT). However, these linear methods may introduce inaccuracies due to noise, lens distortion, and other factors.
ILS leverages the least squares optimization framework to iteratively minimize the difference between the observed image projections of landmarks and their corresponding estimated projections based on the refined 3D positions. In each iteration, the algorithm adjusts the 3D positions of landmarks to minimize the error between observed and estimated projections. This process iteratively improves the triangulation results and provides more accurate 3D coordinates.
2.3 Non-linear Triangulation
Non-linear triangulation methods use non-linear optimization techniques to directly estimate the 3D position of map points by minimizing the reprojection error. These methods often yield better results than linear methods, especially in
scenarios with significant noise or challenging lighting conditions.
Principle of Nonlinear Triangulation:
Nonlinear triangulation extends the concept of iterative optimization to address inaccuracies introduced by linear triangulation methods. It starts with an initial estimate of the 3D point positions based on observed 2D image points and corresponding camera poses. However, instead of treating the triangulation as a purely linear problem, nonlinear triangulation considers the impact of lens distortion, noise, and other non-linear effects.
The technique employs optimization algorithms, such as Levenberg-Marquardt or Gauss-Newton, to iteratively minimize the difference between the observed 2D projections of landmarks and their estimated projections based on the refined 3D positions. This iterative process refines the 3D coordinates of landmarks to more accurately align their projected positions with the observed image points.
3. Map Point Creation
Once the 3D positions of map points are estimated through triangulation, the visual SLAM system creates a map of the environment. The map points represent distinctive features in the scene that the robot can use for localization and navigation.
3.1 Map Representation
The map created by the visual SLAM system can be represented in different forms, such as a sparse or dense 3D point cloud, a keyframe-based map, or a feature-based map. Each representation has its advantages and is selected based on the specific application requirements and computational resources available.
Sparse 3D Point Cloud:
-
- In a sparse 3D point cloud representation, the SLAM system maintains a collection of 3D points that represent key features or landmarks in the environment. These points are typically sparse, meaning that only a subset of distinctive and salient features from the scene is used for mapping.
-
- Each 3D point is associated with a set of 2D image keypoints observed across multiple camera frames, allowing the SLAM system to estimate their 3D positions and camera poses simultaneously.
-
- The sparse 3D point cloud is memory-efficient and useful for real-time applications, but it might not provide a complete representation of the environment.
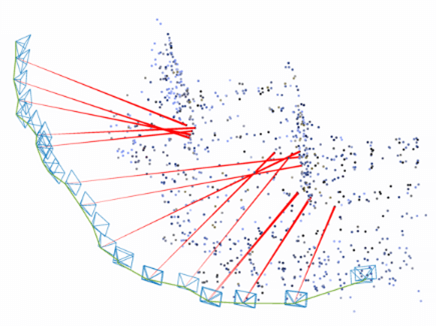
Keyframe-Based Map:
-
- In a keyframe-based map, the SLAM system selects a subset of keyframes from the camera stream to represent the environment. Keyframes are frames with significant motion or high information content.
-
- The keyframe-based map stores both camera poses and sparse or dense 3D points observed in those keyframes. These 3D points are triangulated from the feature matches between consecutive keyframes.
-
- This representation offers a compact and efficient way to represent the map, as it focuses on important moments in the camera trajectory while still capturing relevant environmental features.
Feature-Based Map:
-
- A feature-based map represents the environment using distinctive visual features extracted from the camera images.
-
- The map consists of a collection of features, such as keypoints, corners, or descriptors, along with their corresponding 3D positions. These features serve as landmarks for tracking and loop closure in the SLAM system.
-
- Feature-based maps can be combined with either sparse or dense 3D point cloud representations to create a more comprehensive map.

3.2 Feature Management
To maintain an efficient map, the visual SLAM system needs to manage the map points effectively. This includes adding new map points as the robot explores new areas, removing redundant or non-informative points to reduce memory usage, and optimizing the map structure to improve overall accuracy.
4. Challenges and Considerations
While triangulation and map point creation are essential steps in visual SLAM, they come with their own set of challenges:
4.1 Ambiguity and Occlusion
In certain scenarios, feature matching and triangulation can suffer from ambiguity due to repetitive patterns or lack of distinctive features. Occlusion, where parts of the scene are hidden from the camera view, can also affect the accuracy of feature matching and triangulation.
4.2 Dynamic Environments
In environments with moving objects, dynamic scenes, or changes in lighting conditions, maintaining a stable and consistent map becomes challenging. The SLAM system must handle dynamic map points and manage their presence in the map. Some key metrics are:
4.3 Real-time Performance
Visual SLAM systems often operate in real-time, requiring efficient algorithms for feature extraction, matching, triangulation, and map point management. Balancing accuracy and computational efficiency is a constant consideration in SLAM development.
- Frame Rate: The number of frames processed per second is a fundamental metric for real-time performance. It indicates how quickly the system can analyze incoming data, make computations, and provide updated information.
- Latency: This measures the delay between the sensor capturing data and the system producing a response. Low latency is critical in real-time applications to ensure the system reacts quickly to changes in the environment.
- Processing Time: It quantifies the time taken to perform specific computations, such as feature extraction, matching, triangulation, and map point management. Lower processing times indicate more efficient algorithms and implementations.
- CPU/GPU Utilization: Monitoring the usage of computational resources like CPU and GPU helps ensure the system is not overloaded. Efficient algorithms should utilize resources optimally without maxing out hardware capabilities.
- Memory Usage: Assessing how much memory the SLAM system consumes is crucial, especially for embedded or resource-constrained devices. Efficient algorithms use memory judiciously to store data and maintain functionality.
- Accuracy vs. Speed Trade-off: This metric balances the accuracy of the SLAM system against its speed. Systems often need to trade off accuracy to achieve real-time performance. Analyzing this trade-off helps developers choose the right compromise for their specific application.
Conclusion
Triangulation and map point creation are fundamental steps in visual SLAM that enable the creation of accurate 3D maps from camera images. Through triangulation, the system estimates the 3D positions of distinctive map points by identifying their projections in multiple images. These map points are then used to create a map of the environment, enabling the robot to localize itself and navigate its surroundings. Robust triangulation and map point creation are crucial for the success of visual SLAM systems, especially in challenging scenarios with dynamic environments and real-time requirements. As SLAM technology continues to advance, the development of efficient and accurate triangulation and map point creation methods remains a vital area of research and innovation.

























