
Modern SaaS deployments rely on Serverless computing, allowing software components to be scaled easily with very little management overhead. AI workload execution has also started relying heavily on this technology to allow training or serving of ML models for a variety of applications. During model serving, software components like AI models, preprocessing and postprocessing can be executed as Serverless tasks. This allows efficient utilization of resources available to the serving infrastructure while processing requests from many users simultaneously.
In this article, we explore the usage of Celery as the framework for model training and serving in the context of Ignitarium’s Deep Learning based Infrastructure and Industrial analytics platform – TYQ-i™.
1. Celery
Celery is a distributed task queue implementation for executing tasks in parallel. These task queues are used as a mechanism to distribute work across threads, processors, and machines.
The major components of Celery are:
- A broker or message queue where tasks are stored. A task represents an activity to be completed or executed. The default Celery broker is RabbitMQ.
- A backend that stores the results of a task execution to be retrieved later. Redis is the backend preferred by Celery.
- A process called worker that runs on CPU or GPU and executes a task from the task queue.
2. TYQ-i SaaS platform
The TYQ-i SaaS Platform (TSP) is Ignitarium’s proprietary AI platform used for anomaly detection in infrastructure or industrial applications. The architecture allows public cloud, private cloud, or standalone modes of deployment. Typical use cases include detection of defects in rail tracks, wind turbines, pipelines, roads, towers, bridges, tunnels, canals, or any other civil infrastructure. Industrial shopfloor applications include analytics of parts on a manufacturing assembly line.
2.1 TSP software stack
Figure 1 depicts the high-level view of the TSP software stack when Celery is used as the underlying task distribution framework.
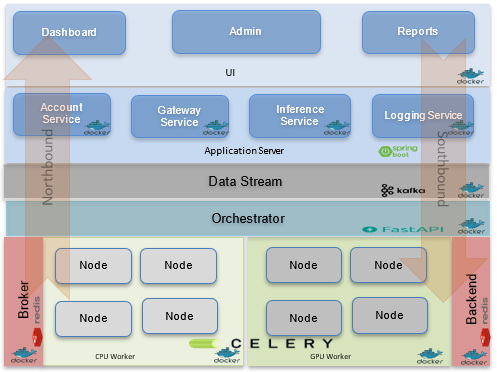
The TSP architecture is highly layered, disaggregating control and data flows in a modular fashion. A well-defined protocol – called the TYQ-i Protocol (TP) – governs communication between logical layers and components within a layer.
The platform considers all components that are implemented in a project as a Node. A Node is the smallest executable component in the TSP and it is mapped to a task in Celery. A Node has an input, an output, and a processing unit. Nodes communicate using the schema defined in the TP. A model or pre or post processing component can be encapsulated into a Node. These Nodes may be executed in parallel or in sequence based on the specific application use case.
2.2 Celery-associated TSP Components:
This section describes the major interfaces and infrastructure components of the platform that are influenced by Celery. Figure 2 shows the high-level components and data flow of the serving platform using Celery.
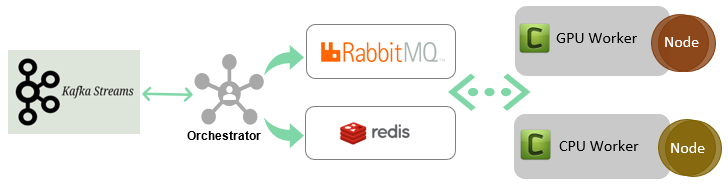
2.2.1 Data Streams
Apache Kafka is used to stream data to the Nodes.
2.2.2 Orchestrator
The sequence of execution of Nodes is controlled by the orchestrator module. Every project in the platform has a workflow. The workflow depicts the parent child relationship and the execution flow of various Nodes that constitute a project. The orchestrator generates a Directed Acyclic Graph (DAG) workflow for any project using this execution flow.
2.2.3 Message Broker
The platform uses RabbitMQ as the Celery broker and Redis as the backend for communication. The orchestrator invokes a task (Node) from the workflow by submitting a Celery task to the Broker. The data (eg. image or video) to be inferenced is written to Redis before invoking a task. Upon receiving the task execution request, a Node will retrieve the input image or data from Redis by using the key provided as part of the input argument to the task invocation.
The Celery worker executes the task (Node) and after execution the result is written back to Redis. The orchestrator schedules the next task, and the scheduled task returns the result via the backend. The Node publishes the task execution results back to the orchestrator using Redis. The orchestrator converts the result to the TYQ-i Protocol (TP) and delivers the same to the northbound interfaces of the TSP.
3.0 Scaling up with Celery workers
One of the major features of Celery is that it is asynchronous. One may add more workers to listen in to a queue and execute work in parallel if the tasks are taking too long.
Each Node in a project is encapsulated within a Celery task and this encapsulation helps a Node to execute exploiting the distributed infrastructure. The distributed task queues allow the platform to scale horizontally (eg. by setting up Celery workers as a Kubernetes pod); it also helps the distribution of GPU and CPU activities to separate queues on the same machine. Celery is also configured to use both process and thread pool execution modes to ensure that all the cores in each machine are being efficiently used.
- 3.1 Performance improvement with Celery
- 3.1 Performance improvement with Celery
3.1.1 Multiple Queues
Separating the tasks in Celery into different queues is the key to improving performance. If there are both tasks which are executed in a short time span and tasks which are time consuming, then they need separate queues. Another benefit from the multi-queue setup is that it enables scaling the number of workers for each queue independently.
3.1.2 Configuring Celery pool and concurrency
Celery offers different ways of running tasks using the “pool” option. We must select the “pool” based on the type of task we are running (CPU or I/O or Network bound).
We can run Celery with the following “pool” settings.
- solo
- prefork
- eventlet
- gevent
Selecting pre-fork and setting the concurrency level to the number of CPU cores is the best option for CPU bound tasks.
4.0 Conclusion
Celery is a very powerful framework with maximum benefits realized via the optimal usage of its numerous options. Configuring the pool, concurrency level, separation of queues, choosing the number of workers, etc. are some of the ways to improve the performance of the overall pipeline. Ignitarium’s TYQ-i™ SaaS Platform (TSP) leverages highly tuned and customized Celery based components to deliver high performance AI pipelines for anomaly detection in industrial and civil infrastructure use cases.

























