
Photo by CHUTTERSNAP on Unsplash
Roads and water canals have historically been opening up channels of commerce in economies across the world and continue to do so even today. The socio-economic development of many countries has been linked to the development and maintenance of infrastructure.
As countries spend billions of dollars on maintenance of such infrastructure, which gets damaged and deteriorates over time, technological advancements in the areas of artificial intelligence and computer vision promise an efficient and automated alternative to traditional maintenance methods.
While highway maintenance includes checking carriageway potholes, guardrails, road markings and uneven footpaths, canal maintenance involves removal of silt and vegetation, repair of collapsed slopes, maintenance of culverts and weirs.
Leveraging AI for efficient maintenance
Maintenance can be approached either by manual inspection like addressing the damage which has already occurred, then fixing it or through an approach of trying to prevent the damage with the help of proactive technologies. Recent advances in Artificial Intelligence, Computer Vision, cloud-based technologies, analytics and the Internet Of Things (IoT) make it possible to automate periodic inspections and thus reduce maintenance costs.
Here, we describe a method for high-throughput analysis of infrastructure assets like roads and canals using cameras mounted on an aerial platform. Roads and canals are curvilinear structures that ‘snake’ over hundreds of miles of terrain. In addition to the inherent non-linear shape of these infrastructure, the platform on which the camera is mounted is unstable. As the aircraft pitches, yaws, and rolls during flight, the “object” that is being video-graphed – the road or the canal – constantly moves out of the field of view. If a good field of view is not constantly maintained, it is not possible to perform useful analytics on the captured footage.
In the following sections, we outline a method that we implemented to perform real-time road and canal ‘following’ by dynamically adjusting the position of the camera such that the road or the canal is always perfectly centered in the camera frame. As previously described, perfect centering, subsequently allows advanced analytics to be run on these images as the most important features of the road or the canal will be always visible.
A high-level flow diagram of the AI-based contour tracker that we implemented is illustrated below:
Contour Tracker Flow
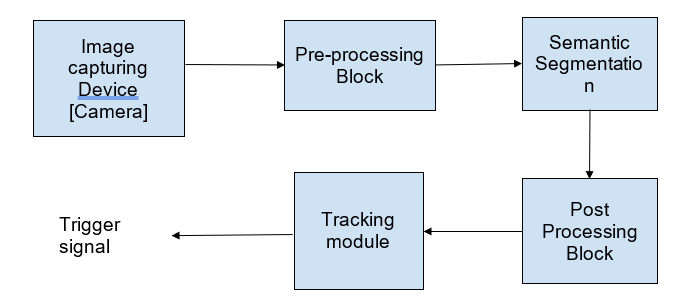
Data Preparation
Raw images of roads and canals are captured from video clips, and more data collected from the internet. Images are labelled with freely available Labelling tools such as LabelMe. The Labelling process is a crucial part for any deep learning-based application. Labelling is done with tight polylines, and annotations are saved in a json format. These labelled images and corresponding labels are used for further pre-processing followed by training.
Semantic Segmentation
UNET
Here, for our problem definition, we’ve used semantic segmentation. Semantic segmentation is the process of classifying every pixel in an image to a certain class, so in brief, it is a classification problem.
For Road and Canal detection, we have implemented a custom semantic segmentation engine. However, for the purposes of this article, we will describe the general approach using the well-known Unet with MobilenetV2 as encoder. Unet is widely used for biomedical image segmentation. The Unet architecture is based on a fully convolutional network. One of the benefits of using Unet is, with a very small dataset, it will give better accurate segmented results. The original paper can be found [Here].
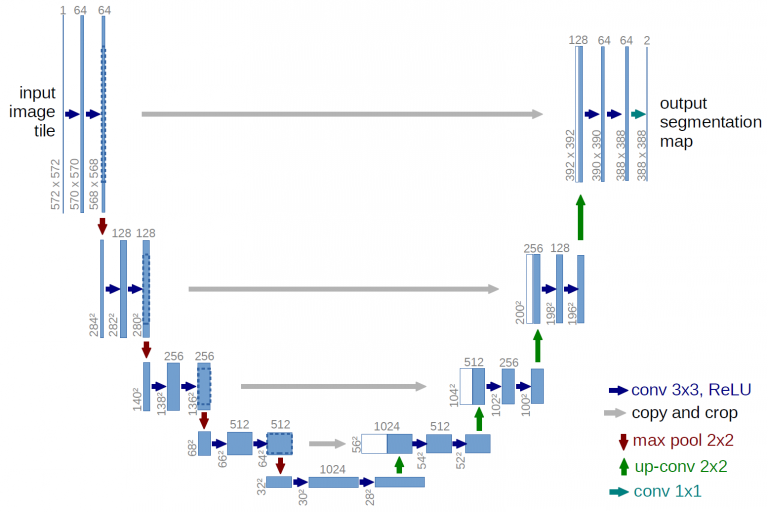
UNET Architecture[Source https://arxiv.org/pdf/1505.04597]
MobileNet V2
Mobilenet V2 is optimized for mobile devices, Since it has less parameters, it is easier to run on any mobile/edge devices as a light feature extractor. The building block of MobilenetV2 consists of separable depth wise convolutions. Linear bottlenecks between the layers and shortcut connections make it different from the earlier version MobilenetV1.
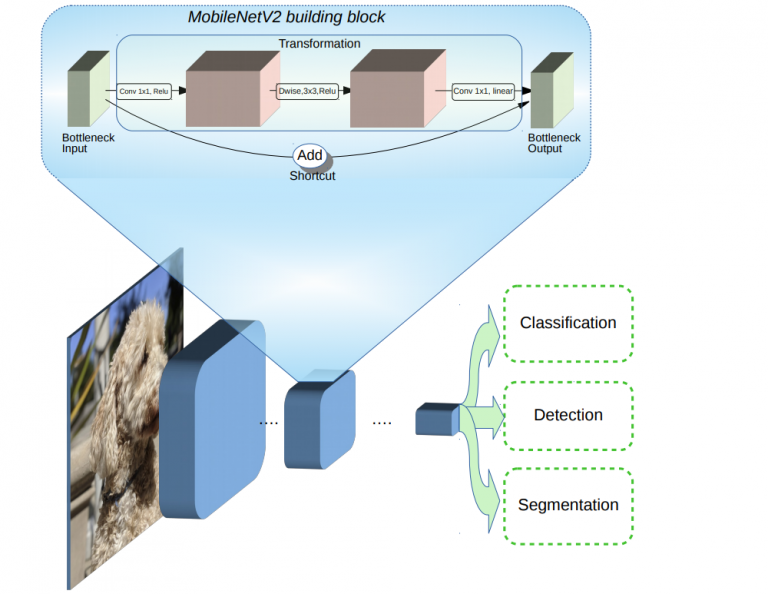
MobilenetV2 Architecture[Source https://ai.googleblog.com/2018/04/mobilenetv2-next-generation-of-on.html]
Image Processing
Raw image collected from the camera is pre-processed before feeding to the model. Collected images need to be resized to the model input size. Since Road and Canal detection needs larger spatial information, input dimension to the model is set to 620 X 480.
Tracking Module
Tracking module is integrated next to the segmentation block, which will calculate pitch, roll and yaw axis rotations needed to control the gimbal or camera mount.
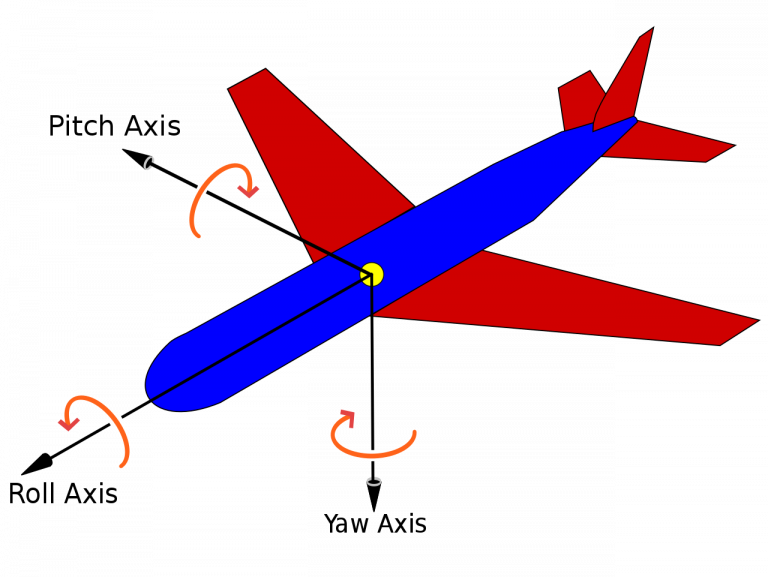
Pitch Roll Yaw interpretation[Source https://en.wikipedia.org/]
Roll is the rotation around the front-to-back axis, Pitch is the rotation around the side-to-side axis, and Yaw corresponds to the rotation around the vertical axis.
These calculations are done after getting a detection image from the segmentation block. For every segmented bounding box, the average centroid is calculated and this centroid and static image centroid is used for calculating the control directions. Image post-processing operations are handled in the post-processing block. Three-State signals [Neutral, Up, and Down] are generated from the Tracking module, and these are used to trigger the electronics that control the motion of the gimbal on which the camera is mounted.

Road Tracking Output streaming sample
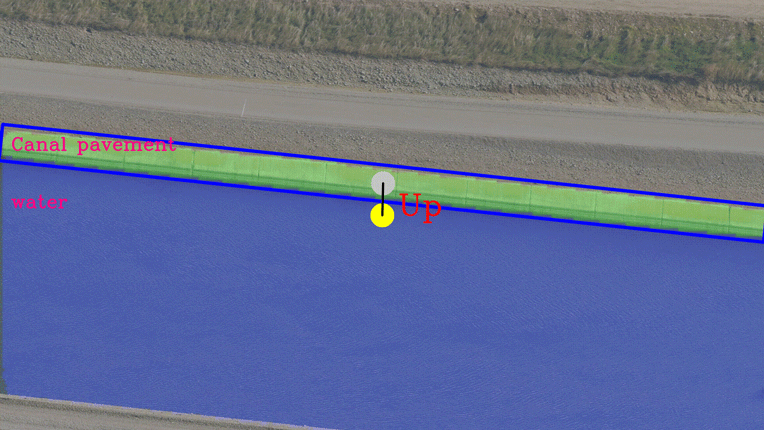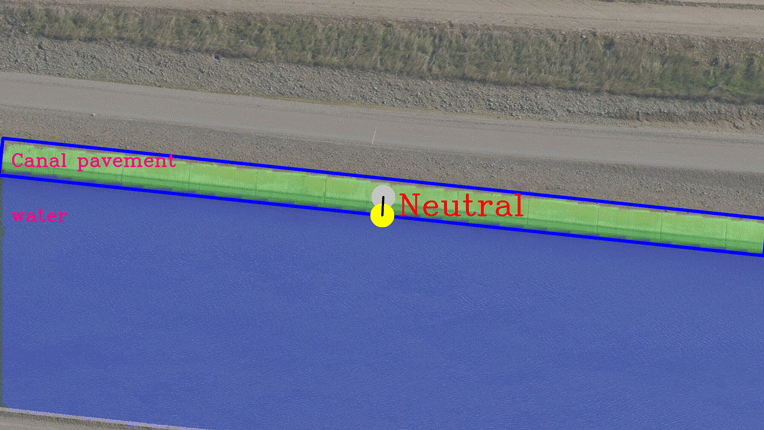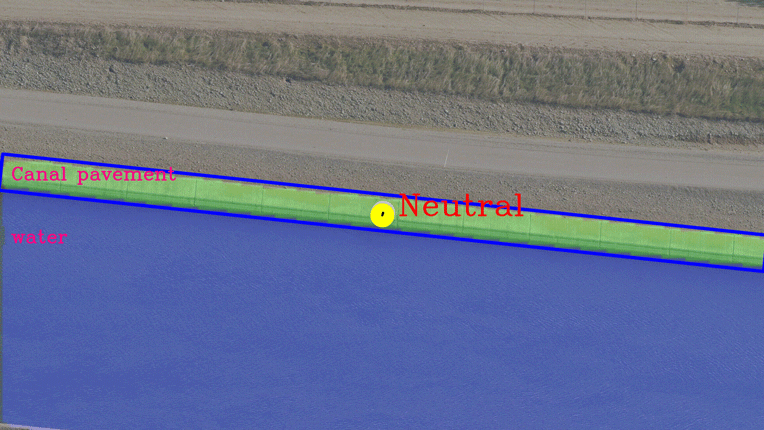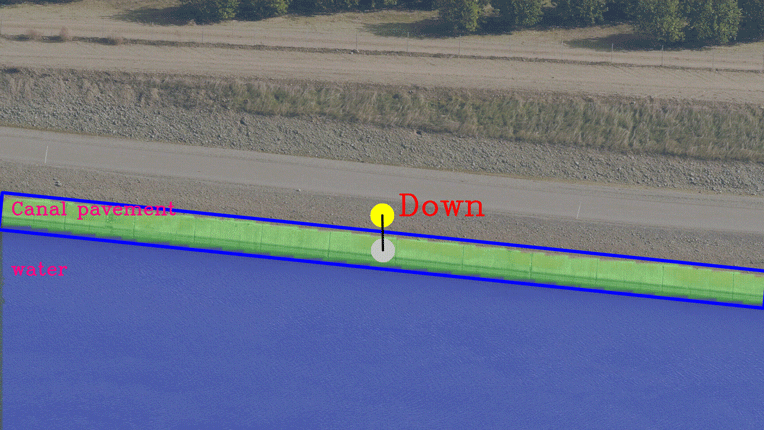
Canal Tracking Output streaming sample
In the above clips, you will observe that the road or canal contour is moving up or down with reference to the complete image frame in response to the UP, DOWN, NEUTRAL signaling generated by the Tracking algorithm.
The tracking algorithm has been deployed on an NVIDIA Jetson TX2-based compute box and is capable of gimbal position correction within less than a few 100ms.
Conclusion
The tracker module for road and canal following is a vital component for aerial data acquisition companies to ensure perfect image capture during flight. These captured images can then be fed into downstream analytics software that can find anomalies or other important artifacts on-road and canal assets.


























2 thoughts on “AI-based Automatic Contour-following of Roads and Canals”
Your article helped me a lot, is there any more related content? Thanks!
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.