
As people around the world prepare to get back to work in the new normal, workplaces are leveraging cutting-edge tech-driven solutions to ensure safety standards for all. AI-driven computer vision systems are being deployed by companies to enforce and monitor social distancing, detecting violations of face masks and safety jackets on their premises.
As governments and companies are coming to rely on AI for these critical everyday tasks, a robust system was envisioned and built by our engineering team using Ignitarium’s proprietary computer vision tech called FLK-i.
The system is built to automate the task of verification of attire in the company or factory premises, namely mask and jacket so as to give or deny access to a person. The system also validates the requisite positional characteristics, i.e., just holding a mask or wearing it improperly around the face won’t suffice to gain access. The mask has to be worn correctly by the person to gain access to restricted areas. The approach taken by the Ignitarium engineering team is detailed in subsequent sections:
- Dataset preparation
- Labelling
- Approach to solving the problem
- Person Detection Model Selection
- Classification of Detected Images
Dataset Preparation
In order to train a model, we must start with the appropriate amount of relevant data. For FLK-i attire and mask detection, we used a variety of data sources: use of open-source datasets, engagement of 3rd party data collection agencies, internal collection via colleagues, general crowd-sourcing, and the use of actual field data. Using the corpus of collected images, we create custom datasets using a combination of selective manual segregation and image processing based binning.
Labelling
Labelling is an important part of any ML-based system. The model training yields maximum accuracy only if the labels are correct. During the initial phases of model evolution, manual labeling is employed. As the model gains maturity, we use the ‘auto-label’ mode of our application framework to leverage person detection models to dump labeled images. Over a period of time, as the model started improving, the focus shifted to dumping false-positive images using updated weights to tune our models on failure cases and prevent data redundancy on those classes of images that are already correctly predicted.
Approach to solving the problem
The approach to solving the problem is to use a detection network in order to identify the presence of a human in the camera feed as well as get the coordinates of the person within the frame. Once this is done, we proceed with a Classifier for each type of attire to determine whether the attire is worn by the person detected in a proper manner.
Person Detection Model Selection
The application currently has two different methods of detecting attire: namely usage of Single Shot detectors and Pose estimators. SSD utilizes the entire image collected for detection purposes whereas pose estimation automatically identifies the face and body region of each person being tested and identifies the attire based on these regions detected within the image.
While custom implementations are used in our application, the following sections describe the general approach using well-known SSD and pose estimation architectures.
Mobilenet-SSD Model
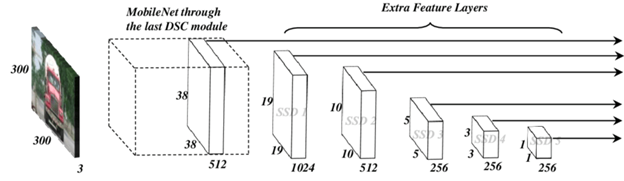
Source: link
Single-shot detector-MobileNet (SSD) models have proven ability to detect and delineate object boundaries as well as have the ability to perform tracking. The input dimensions of the images to the model used is 224x224x3.
If the person is detected, a bounding box will be drawn in real-time over the same to confirm the person is detected. Once the same is validated, the app will proceed to the detection of attire.
Posenet Model
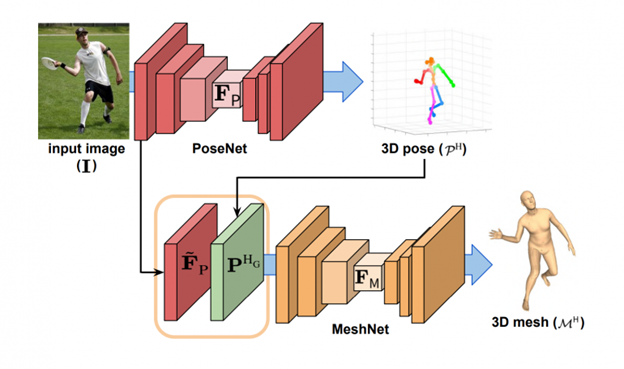
Source: link
PoseNet is a recent launch from Google that can be used to estimate the pose of a person in an image or video by estimating where key body joints are. We developed custom algorithms to then proceed with identifying the location and alignment of the body areas of interest namely body for jacket attire detection and head for mask detection. The input dimensions of the images to the model used is 224x224x3.
This method works by identifying Face and Body regions in the image. This is done by the AI automatically detecting different body and face features of the human body and after the required features are validated, it will proceed to the detection of attire.
The Posenet repository is available for reference here:
https://github.com/tensorflow/tfjs-models/tree/master/posenet
https://github.com/infocom-tpo/tf-openpose
Classification of Detected Images
Once the detections from either of the detection models is available it is passed through a Mobilenet architecture based classifier, employing residual layers as well as depthwise and pointwise convolution layers.
In the case of SSD, the entire crop of the region detected as a person is passed over to two classifiers – one for mask check and another for jacket attire check presence.
Application Snapshots
Here are some of the snapshots of the application:

Application startup screen
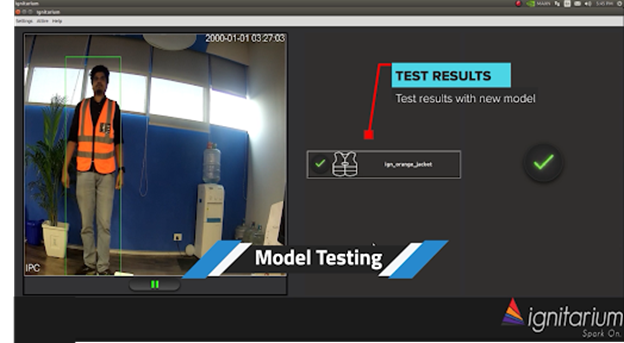
The following are sample images of the application detecting persons wearing and not wearing the prescribed jacket.
Application screenshot of a person not wearing jacket attire
Application screenshot of the person wearing jacket attire
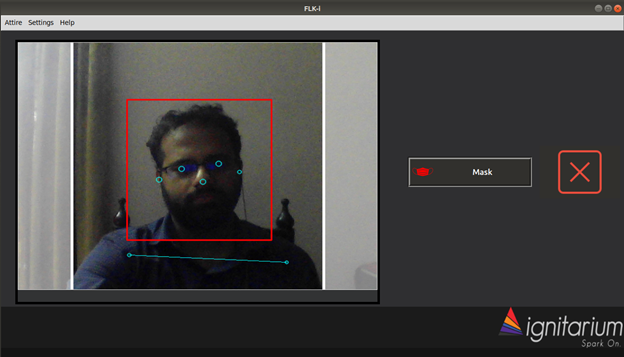
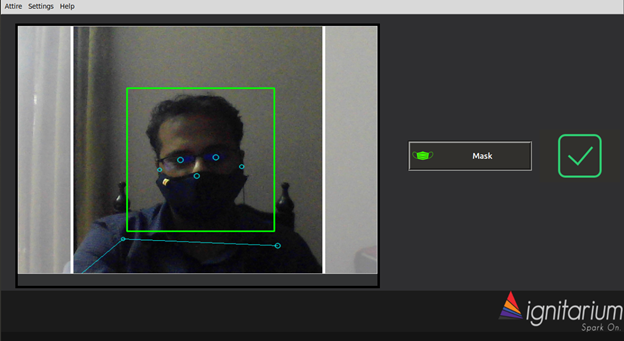
The images below are the snapshots for the application when it detects the presence of a person and checks for mask attire.
Application screenshot of a person not wearing mask attire
Application screenshot of a person wearing mask attire
Performance
The FLK-i attire detection module is implemented on a host of hardware platforms ranging from NPX i.MX8 to the NVIDIA Jetson family. Accuracy levels achieved are 95%+ and the fps (frames per second) range from 2fps to 15fps.
Conclusion
The task of attire and mask detection was solved using customized detectors, pose estimators, and classifiers. The deep learning models were trained so as to also take into consideration the required positional factors. The resulting solution has been successfully tested and deployed in the field.
As more employees all over the world get back to their workplaces, their safety and wellbeing has become the number one priority of employers across industries. Ignitarium’s AI engineering teams have been quick in responding to the needs of companies during the pandemic and are continuously creating solutions using AI that are relevant and reliable.


























{kind=link}
{kind=link}
41 thoughts on “AI-driven Face Mask and Attire Detection for the new normal”
acheter medicament sans ordonnance: antalgique sans ordonnance – tadalafil 20 mg sans ordonnance
acheter betamethasone sans ordonnance: cortisone sans ordonnance – ordonnance tadalafil
http://zorgpakket.com/# medicatielijst apotheek
https://tryggmed.shop/# er apoteket åpent i dag
hansker apotek [url=http://tryggmed.com/#]apotek sverige[/url] sovemaske apotek
belgische online apotheek: pillen bestellen – medicijnen kopen
medicijn bestellen apotheek: MedicijnPunt – medicijnlijst apotheek
https://snabbapoteket.com/# beställa medicin online
klorhexidin apotek [url=https://tryggmed.shop/#]Trygg Med[/url] hГҐrfiber apotek
kjГёpe medisin pГҐ nett: TryggMed – mygg klistremerker apotek
medicijnen online kopen: medicijnen zonder recept kopen – frenadol kopen in nederland
http://zorgpakket.com/# medicijnen aanvragen
https://zorgpakket.com/# online apotheek nederland zonder recept
tandblekning apotek [url=http://snabbapoteket.com/#]kolla recept apotek[/url] skänka blöjor
riklig mens vid 50 Г¤r: apotek fullmakt blankett – mens tabletter
jobbar pГҐ apotek: se recept online – l-serin apotek
https://tryggmed.com/# aptoek
alfa liponsyre apotek: Гёreskyll apotek – dГҐrlig ГҐnde apotek
skillnad bb och cc cream [url=http://snabbapoteket.com/#]e apotek[/url] köpa medicin på nätet utan recept
bestГ¤lla nГ¤ringsdryck pГҐ recept: SnabbApoteket – antigentest apotek
https://tryggmed.shop/# legevakten apotek
https://tryggmed.com/# sjampo mot flass apotek
sax pГҐ engelska: SnabbApoteket – sverige apotek
Гёrespray apotek [url=http://tryggmed.com/#]TryggMed[/url] akupunkturnГҐler apotek
pregnancy test apotek: SnabbApoteket – apotek fullmakt
https://zorgpakket.shop/# online medicatie bestellen
tandvГҐrd gravid gratis: SnabbApoteket – rabattkod apotek
apteka nl [url=https://zorgpakket.com/#]medicijn bestellen[/url] de apotheker
magnesium apotek: Гёrevoks apotek – urinveisinfeksjon apotek
http://snabbapoteket.com/# express apotek
https://tryggmed.com/# varmepose apotek
cheap cialis mexico: best mexican pharmacy online – MediMexicoRx
http://medimexicorx.com/# MediMexicoRx
viagra online pharmacy prices [url=https://expresscarerx.online/#]ExpressCareRx[/url] euro pharmacy cialis
accutane mexico buy online: legit mexico pharmacy shipping to USA – MediMexicoRx
IndiaMedsHub: mail order pharmacy india – buy medicines online in india
http://medimexicorx.com/# reputable mexican pharmacies online
reputable indian online pharmacy [url=https://indiamedshub.shop/#]Online medicine home delivery[/url] IndiaMedsHub
http://indiamedshub.com/# IndiaMedsHub
ExpressCareRx: testosterone cream online pharmacy – pharmacy price of viagra
http://indiamedshub.com/# reputable indian online pharmacy