
1. Introduction
In this article we explore the advantages of making use of the native APIs and runtime engine of OpenVINO to maximize the performance and efficiency of DNN model inference. The exploration was conducted on Ignitarium’s proprietary anomaly detection platform, TYQ-i™, using our custom models targeting the detection of defects on telecom towers.
1.1 Brief summary of OpenVINO
OpenVINO (Open Visual Inference and Neural Network Optimization) is a software toolkit developed by Intel Corporation that enables the creation and deployment of Deep Learning applications. The main functionality of this toolkit is that it can be used to customize the inference architecture and deploy it specifically on Intel hardware-based platforms.
OpenVINO has an open-source support community and offers multiple pre-trained and deployable models for quick inference. It allows the optimization of DNN models, streamlining and efficient processing through the integration of various tools.
Benefits of using OpenVINO:
* Performance acceleration and model customization
* Optimization of models from various frameworks like TensorFlow, PyTorch etc.
* It can perform traditional computer vision tasks as well.
Limitations:
* OpenVINO cannot run non vision based machine learning algorithms.
2. TYQ-i SaaS platform overview
We run the OpenVINO experiments on the SaaS version of our TYQ-i Platform targeting an Intel TigerLake-UP3-based compute box. The TYQ-i platform was conceptualized to provide various AI services to end users using edge or cloud configurations. At a very high level, the platform has 3 main components:
2.1. Front end
The Front end enables the user to upload input data as either video or frames which will be consumed and processed by the data inference pipeline. The user can configure the tasks needed to be performed during the data inference.
2.2. Orchestrator-service
The Orchestrator-service implements Kafka consumers and producers for communication between front end and inference nodes. It is an entity which manages the complete lifecycle of the inference execution. The components of the Orchestrator are:
- Kafka consumer to input frames
- Kafka producer to publish the output frames
- Workflow to orchestrate the sequence of execution of nodes
Each TYQ-i project has a well-defined workflow. The workflow obeys a parent child relationship and controls the execution sequence of all the nodes activated for the specific project. The orchestrator generates a Directed Acyclic Graph (DAG) workflow for any project using this execution flow.
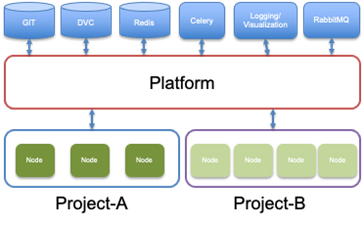
2.3. Model-Platform
The primary functionality of the Model-platform is to deliver the relevant input files to the various nodes via a well-defined pipeline. The platform makes use of Celery workers to execute the defined tasks. The workers will fetch input data from the storage (Redis) and executes the task (Node). After the task is complete, the results are then written back to Redis, subsequent tasks are executed, and the results are returned.
3. Example project
A sample application (Tele-tower) from the TYQ-i library was used for this specific OpenVINO-based optimisation exercise. The application uses a set of platform components to ingest a video, perform pre-processing, detect a tele-tower, identify tower joints and uniquely track and detect missing bolts on the joints.
3.1 Process description
The input feed is a video encompassing the whole tower; the field-of-view covers the entire structure starting from the top of the tower and ends at the base. It contains multiple frames with overlapping areas between the successive images. The TYQ-i project (application) is designed to detect the required objects and uniquely track them. The redundant detections are discarded later.
After the input frames are uploaded to the data pipeline, the TYQ-i platform will execute all the project nodes and the output is displayed.
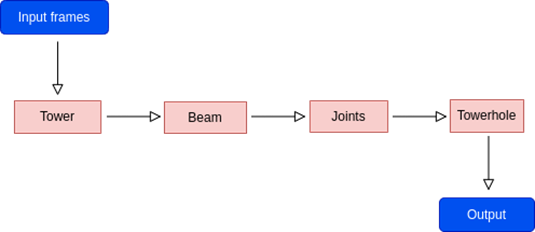
The above flow diagram represents the inference workflow. During inference, the detections are obtained in a sequential manner as defined in the diagram. The entire process workflow follows the path defined by the user during project configuration. After all the missing bolts (towerhole) are identified in the input image, they are then tracked through the video to make sure that the redundant detections are eliminated and only the unique detections are recorded.
3.2 Tracker module
When the tracker is enabled, the results obtained after the input image is processed will be run through the tracker module. This module will assign unique Ids to each missing bolt detected and these Ids are stored. If a detection occurs on consecutive frames, and the number of occurrences exceeds a pre-determined threshold, the detection is regarded as unique and then recorded.
However, if the specific use case does not require inter-frame tracking, a Non-tracker mode is selected; the detections obtained after processing (missing bolts in this case) will be simply assigned a unique Id and the output will be displayed. The Ids will be only unique for that particular frame and the same Ids can be reassigned when subsequent frames are processed.
4. OpenVINO inference and testing
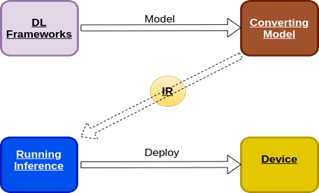
In order to make an inference with the custom DNN models using the native inference engine, we need the models to be compatible with the OpenVINO toolkit. The execution process required to generate the IR models is as follows:
- The pre-trained custom models are fed to the model optimizer provided in the toolkit. The model optimizer then converts it into the intermediate representation (IR) format with .bin and .xml files.
- Next, the inference engine generates the output using the IR model.
4.1 Model Optimizer
Model optimizer is a command line tool that is used to convert a pre-trained model into an OpenVINO compatible model. It can convert any model from the OpenVINO supported formats (eg:- TensorFlow, PyTorch, ONNX etc.) into OpenVINO IR format, which can be later used for inferencing with the OpenVINO runtime.
4.2 Inference Engine
The inference engine is a C++ library that consists of the API required for reading the intermediate representation to execute the models.
4.3 Model conversion to IR format
Model optimizer takes in parameters like the input_shape and converts the TF model to .xml and .bin files. Below is an example of the command used.
python3 OpenVINO/model-optimizer/mo_tf.py –saved_model_dir model/ –input_shape=\[1,28,28\]

where IR is a pair of files describing the model:
- .xml file – contains the network topology.
- .bin file – has the weights and biases binary data.
In this experiment, models trained using the Tensorflow framework were used. Since we had a trained model, we need the model optimizer tool to convert the TF model to an OpenVINO IR model.
4.4 Model conversion steps from Tensorflow to OpenVINO format
There are multiple ways of converting a custom TF model into IR format. In our case, we have a custom model in HDF5 format.
In order in to convert to IR format, these steps were followed:
- The Keras H5 model with custom layer is first loaded using tf package and then converted into a saved model format.
- Then the saved model is converted into IR format by making use of the model optimizer script provided by OpenVINO toolkit.
- The operation requires us to specify the input and output options so that the inference batch size and resolutions are maintained.
- The OpenVINO model expects the inference request to be in NCHW format, where N=batch_size, C=size of color channel, H=input height, W=input width.
Further details about the steps discussed above can be found in the OpenVINO documentation in the link below:
https://docs.openvino.ai/2021.3/openvino_docs_MO_DG_Deep_Learning_Model_Optimizer_DevGuide.html
5. Batch Processing in OpenVINO Model Server
Batch processing or batch prediction is the process where we use the trained DNN model to obtain a set of predictions from the input files, thereby reducing the compute time and improving the overall performance. Batch prediction can be made on either a fixed input batch or a varying one.
5.1 Varying batch size approach
By default, the model batch size is fixed for IR models. It is set by the model optimizer tool at the time of model conversion. However, if the size of inference request batch varies, then the OpenVINO toolkit will automatically reload the model with the new batch size.
During our experiment, the application encountered a scenario with varying input batches, causing the model to reload for each new request. This action led to increase in the processing time and the overall performance degraded as a result, hence it became necessary to have a fixed batch size during inference requests.
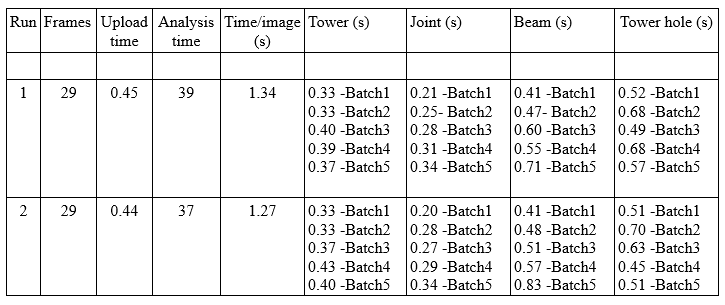
From the results tabulated below we can clearly observe that each time the input data with different batch size is received, the model is reloaded, leading to higher execution times. We also observe an extra response delay for the first request when starting the first execution. This behaviour is repeated in all testing scenarios:
Table 1. The batch wise comparison for DNN nodes execution time (varying batch)
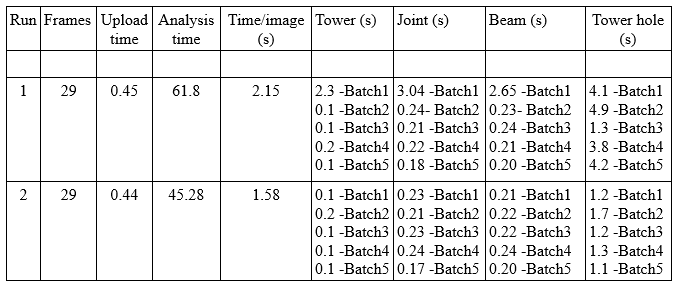
In the results tabulated above,
- The Time/image value is calculated as:
(Analysis time + Upload time) / (total no of frames)
- The Tower, Joint, Beam and Towerhole columns represent the different nodes processed, and contains the time taken to execute the node for a batch of images.
Referring to the batchwise comparison table, we can make the following inference:
The towerhole node has the maximum execution time, when compared to the other nodes for each run. We also observe that the towerhole results show the maximum variation in terms of the time taken to process each batch. This is because the towerhole node has a varying input batch. As the joints detected (parent node) on the frames varies from frame to frame, the input batch size for the subsequent node (towerhole) varies correspondingly. This leads to the model being reloaded every time a new request is received and thus increasing the execution time, which in turn negatively affects the performance.
5.2 Fixed batch size approach:
In order to circumvent the problem of multiple reloads during inference, we adopted a fixed batch size during the pre-processing stage. Corner cases are handled by introducing dummy data/images if the inference requests have the batch size smaller than the fixed size chosen for the project.
By having a fixed batch size during pre-processing, we were able to prevent the model from reloading for each inference request; as a result we get similar time for processing each batch, whereas in the previous runs the processing time varied according to the batch size. Thus, we obtained an overall improvement in FPS. The extra time taken for the first inference run is observed here as well, but the difference is negligible when compared to the previous scenario.
Table 2. The batch wise comparison for DNN nodes execution time (fixed batch)
5.3 Model Caching
While working with GPU devices, we may encounter the problem of higher model loading time which can lead to performance degradation. In order to overcome this, OpenVINO allows caching of inference models.
Enabling this option will allow OpenVINO to check if a model exists in the cache and if it does, it will automatically load it from cache. If the model doesn’t exist in cache, the model is loaded and then later stored in the caching directory for the subsequent runs.
For our experiments we could not make use of model caching as the inference request contained varying input batch size for different capabilities tested leading to automatic model reloading for each new request which in turn reduced the overall performance.
6. Comparison of overall performance
All the experimental runs depicted below were performed by keeping the same system parameters for both GPU and CPU based implementations. For overall comparison study, both the cases were considered (i.e. Tracker module enabled and Tracker module disabled). We ran the tests for overall performance with a fixed batch implementation for multiple batch sizes (namely, 1,4,5,6,10), but there was no significant change in the overall FPS (or inference per frame time). The best execution time was recorded and tabulated.
Table 3. Nodewise comparison of execution time with and without GPU enabled
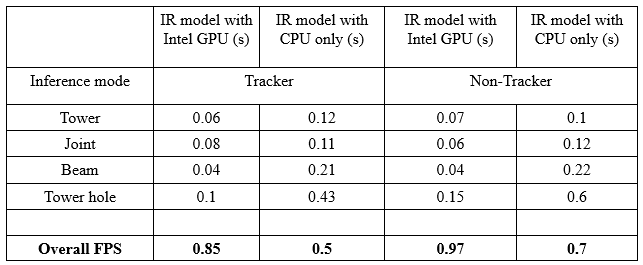
From the results obtained for both the inference modes, we can observe that the overall performance on the Intel TigerLake-UP3 board was best with the GPU enabled OpenVINO implementation.


























{kind=link}
{kind=link}