Abstract
The benefits of Batch Normalization in training are well known for the reduction of internal covariate shift and hence optimizing the training to converge faster. This article tries to bring in a different perspective, where the quantization loss is recovered with the help of Batch Normalization layer, thus retaining the accuracy of the model. The article also gives a simplified implementation of Batch Normalization to reduce the load on edge devices which generally will have constraints on computation of neural network models.
Batch Normalization Theory
During the training of neural network, we have to ensure that the network learns faster. One of the ways to make it faster is by normalizing the inputs to network, along with normalization of intermittent layers of the network. This intermediate layer normalization is what is called Batch Normalization. The Advantage of Batch norm is also that it helps in minimizing internal covariate shift, as described in this paper.
The frameworks like TensorFlow, Keras and Caffe have got the same representation with different symbols attached to it. In general, the Batch Normalization can be described by following math:
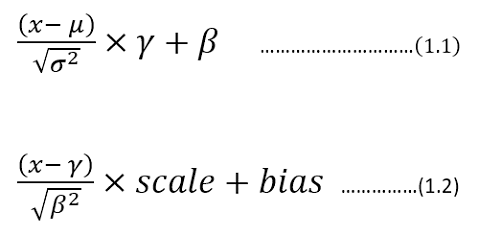
Batch Normalization equation
Here the equation (1.1) is a representation of Keras/TensorFlow. whereas equation (1.2) is the representation used by Caffe framework. In this article, the equation (1.1) style is adopted for the continuation of the context.

Now let’s modify the equation (1.1) as below:
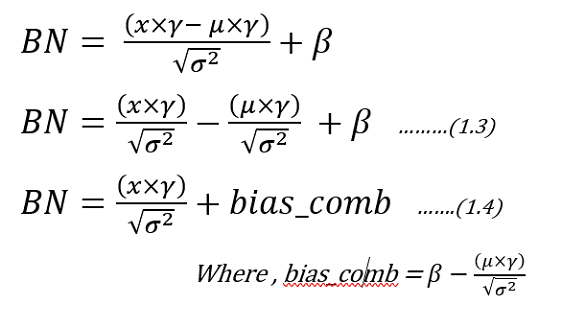
Now by observing the equation of (1.4), there remains an option for optimization in reducing number of multiplications and additions. The bias comb (read it as combined bias) factor can be offline calculated for each channel. Also the ratio of “gamma/sqrt(variance)” can be calculated offline and can be used while implementing the Batch norm equation. This equation can be used in Quantized inference model, to reduce the complexity.
Quantized Inference Model
The inference model to be deployed in edge devices, would generally integer arithmetic friendly CPUs, such as ARM Cortex-M/A series processors or FPGA devices. Now to make inference model friendly to the architecture of the edge devices, will create a simulation in Python. And then convert the inference model’s chain of inputs, weights, and outputs into fixed point format. In the fixed point format, Q for 8 bits is chosen to represent with integer.fractional format. This simulation model will help you to develop the inference model faster on the device and also will help you to evaluate the accuracy of the model.
e.g: Q2.6 represents 6 bits of fractional and 2 bits of an integer.
Now the way to represent the Q format for each layer is as follows:
- Take the Maximum and Minimum of inputs, outputs, and each layer/weights.
- Get the fractional bits required to represent the Dynamic range (by using Maximum/Minimum) is as below using Python function:
def get_fract_bits(tensor_float): # Assumption is that out of 8 bits, one bit is used as sign fract_dout = 7 - np.ceil(np.log2(abs(tensor_float).max()))
fract_dout = fract_dout.astype('int8')
return fract_dout
- Now the integer bits are 7-fractional_bits, as one bit is reserved for sign representation.
4. To start with perform this on input and then followed by Layer 1, 2 …, so on.
5. Do the quantization step for weights and then for the output assuming one example of input. The assumption is made that input is normalized so that we can generalize the Q format, otherwise, this may lead to some loss in data when non-normalized different input gets fed.
6. This will set Q format for input, weights, and outputs.
Example:
Let’s consider Resnet-50 as a model to be quantized. Let’s use Keras inbuilt Resnet-50 trained with Imagenet.#Creating the model
def model_create():
model = tf.compat.v1.keras.applications.resnet50.ResNet50(
include_top=True,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000)
return model
Let’s prepare input for resnet-50. The below image is taken from ImageNet dataset.

def prepare_input():
img = image.load_img(
"D:\\Elephant_water.jpg",
target_size=(224,224)
)
x_test = image.img_to_array(img)
x_test = np.expand_dims(x_test,axis=0)
x = preprocess_input(x_test) # from tensorflow.compat.v1.keras.applications.resnet50 import preprocess_input, decode_predictions
return x
Now Lets call the above two functions and find out the Q format for input.
model = model_create()
x = prepare_input()
If you observe the input ‘x’, its dynamic range is between -123.68 to 131.32. This makes it hard for fitting in 8 bits, as we only have 7 bits to represent these numbers, considering one sign bit. Hence the Q Format for this input would become, Q8.0, where 7 bits are input numbers and 1 sign bit. Hence it clips the data between -128 to +127 (-2⁷ to 2⁷ -1). so we would be loosing some data in this input quantization conversion (most obvious being 131.32 is clipped to 127), whose loss can be seen by Signal to Quantize Noise Ratio , which will be described soon below.
If you follow the same method for each weight and outputs of the layers, we will have some Q format which we can fix to simulate the quantization.
# Lets get first layer properties
(padding, _) = model.layers[1].padding
# lets get second layer properties
wts = model.layers[2].get_weights()
strides = model.layers[2].strides
W=wts[0]
b=wts[1]
hparameters =dict(
pad=padding[0],
stride=strides[0]
)
# Lets Quantize the weights .
quant_bits = 8 # This will be our data path.
wts_qn,wts_bits_fract = Quantize(W,quant_bits) # Both weights and biases will be quantized with wts_bits_fract.
# lets quantize Bias also at wts_bits_fract
b_qn = (np.round(b *(2<<wts_bits_fract))).astype('int8')
names_model,names_pair = getnames_layers(model)
layers_op = get_each_layers(model,x,names_model)
quant_bits = 8
print("Running conv2D")
# Lets extract the first layer output from convolution block.
Z_fl = layers_op[2] # This Number is first convolution.
# Find out the maximum bits required for final convolved value.
fract_dout = get_fract_bits(Z_fl)
fractional_bits = [0,wts_bits_fract,fract_dout]
# Quantized convolution here. Z, cache_conv = conv_forward(
x.astype('int8'),
wts_qn,
b_qn[np.newaxis,np.newaxis,np.newaxis,...],
hparameters,
fractional_bits)
Now if you observe the above snippet of code, the convolution operation will take input, weights, and output with its fractional bits defined.
i.e: fractional_bits=[0,7,-3]
where 1st element represents 0 bits for fractional representation of input (Q8.0)
2nd element represents 7 bits for fractional representation of weights (Q1.7).
3rd element represents -3 bits for the fractional representation of outputs (Q8.0, but need additional 3 bits for integer representation as the range is beyond 8-bit representation).
This will have to repeat for each layer to get the Q format.
Now the quantization familiarity is established, we can move to the impact of this quantization on SQNR and hence accuracy.
Signal to Quantization Noise Ratio
As we have reduced the dynamic range from floating point representation to fixed point representation by using Q format, we have discretized the values to nearest possible integer representation. This introduces the quantization noise, which can be quantified mathematically by Signal to Quantization noise ratio.(refer: https://en.wikipedia.org/wiki/Signal-to-quantization-noise_ratio)
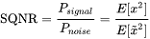
As shown in the above equation, we will measure the ratio of signal power to noise power. This representation applied on log scale converts to dB (10log10SQNR). Here signal is floating point input which we are quantizing to nearest integer and noise is Quantization noise.
example: The elephant example of input has maximum value of 131.32, but we are representing this to nearest integer possible, which is 127. Hence it makes Quantization noise = 131.32–127 = 4.32.
So SQNR = 131.32² /4.32² = 924.04, which is 29.66 db, indicating that we have only attained close to 30dB as compared to 48dB (6*no_of_bits) possibility.
This reflection of SQNR on accuracy can be established for each individual network depending on structure. But indirectly we can say better the SQNR the higher is the accuracy.
Convolution in Quantized environments:
The convolution operation in CNN is well known, where we multiply the kernel with input and accumulate to get the results. In this process we have to remember that we are operating with 8 bits as inputs , hence the result of multiplication need at least 16 bits and then accumulating it in 32 bits accumulator, which would help to maintain the precision of the result. Then result is rounded or truncated to 8 bits to carry 8 bit width of data.
def conv_single_step_quantized(a_slice_prev, W, b,ip_fract,wt_fract,fract_dout):
"""
Apply one filter defined by parameters W on a single slice (a_slice_prev) of the output activation
of the previous layer.
Arguments:
a_slice_prev -- slice of input data of shape (f, f, n_C_prev)
W -- Weight parameters contained in a window - matrix of shape (f, f, n_C_prev)
b -- Bias parameters contained in a window - matrix of shape (1, 1, 1)
Returns:
Z -- a scalar value, result of convolving the sliding window (W, b) on a slice x of the input data
"""
# Element-wise product between a_slice and W. Do not add the bias yet.
s = np.multiply(a_slice_prev.astype('int16'),W) # Let result be held in 16 bit
# Sum over all entries of the volume s.
Z = np.sum(s.astype('int32')) # Final result be stored in int32.
# The Result of 32 bit is to be trucated to 8 bit to restore the data path.
# Add bias b to Z. Cast b to a float() so that Z results in a scalar value.
# Bring bias to 32 bits to add to Z.
Z = Z + (b << ip_fract).astype('int32')
# Lets find out how many integer bits are taken during addition.
# You can do this by taking leading no of bits in C/Assembly/FPGA programming
# Here lets simulate
Z = Z >> (ip_fract+wt_fract - fract_dout)
if(Z > 127):
Z = 127
elif(Z < -128):
Z = -128
else:
Z = Z.astype('int8')
return Z
The above code is inspired from AndrewNg’s deep learning specialization course, where convolution from scratch is taught. Then modified the same to fit for Quantization.
Batch Norm in Quantized environment
As shown in Equation 1.4, we have modified representation to reduce complexity and perform the Batch normalization.The code below shows the same implementation.
def calculate_bn(x,bn_param,Bn_fract_dout):
x_ip = x[0] x_fract_bits = x[1]
bn_param_gamma_s = bn_param[0][0]
bn_param_fract_bits = bn_param[0][1]
op = x_ip*bn_param_gamma_s.astype(np.int16) # x*gamma_s
# This output will have x_fract_bits + bn_param_fract_bits
fract_bits =x_fract_bits + bn_param_fract_bits
bn_param_bias = bn_param[1][0]
bn_param_fract_bits = bn_param[1][1]
bias = bn_param_bias.astype(np.int16)
# lets adjust bias to fract bits
bias = bias << (fract_bits - bn_param_fract_bits)
op = op + bias # + bias
# Convert this op back to 8 bits, with Bn_fract_dout as fractional bits
op = op >> (fract_bits - Bn_fract_dout)
BN_op = op.astype(np.int8)
return BN_op
Now with these pieces in place for the Quantization inference model, we can see now the Batch norm impact on quantization.
Results
The Resnet-50 trained with ImageNet is used for python simulation to quantize the inference model. From the above sections, we bind the pieces together to only analyze the first convolution followed by Batch Norm layer.
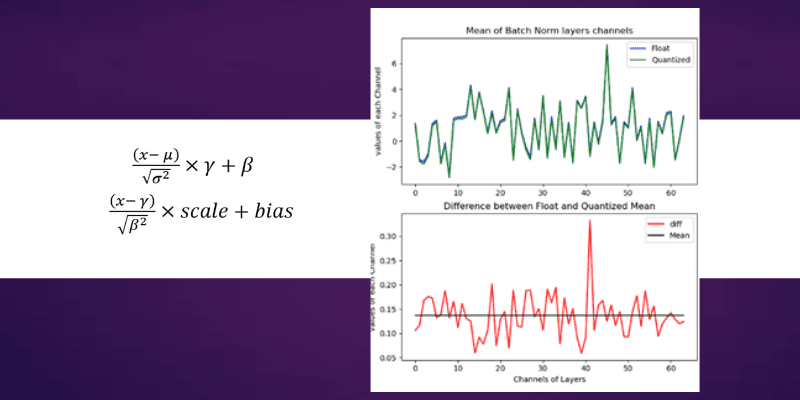
The convolution operation is the heaviest of the network in terms of complexity and also in maintaining accuracy of the model. So let’s look at the Convolution data after we quantized it to 8 bits. The below figure on the left-hand side represents the convolution output of 64 channels (or filters applied) output whose mean value is taken for comparison. The Blue color is float reference and the green color is Quantized implementation. The difference plot (Left-Hand side) gives an indication of how much variation exists between float and quantized one. The line drawn in that Difference figure is mean, whose value is around 4. which means we are getting on an average difference between float and Quantized values close to a value of 4.
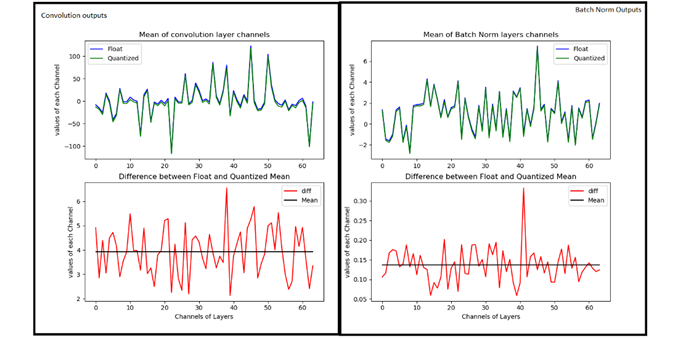
Convolution and Batch Norm Outputs
Now let’s look at Right-Hand side figure, which is Batch Normalization section. As you can see the Green and blue curves are so close by and their differences range is shrunk to less than 0.5 range. The Mean line is around 0.135, which used to be around 4 in the case of convolution. This indicates we are reducing our differences between float and quantized implementation from mean of 4 to 0.135 (almost close to 0).
Now let’s look at the SQNR plot to appreciate the Batch Norm impact.
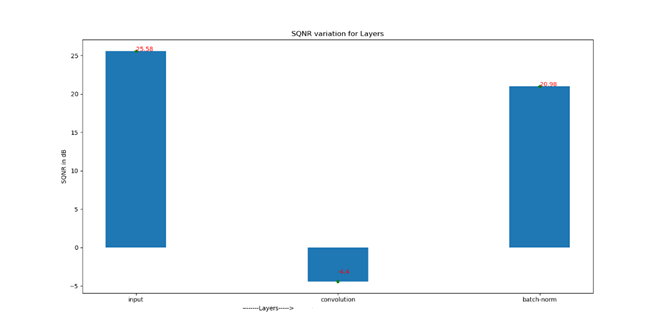
Signal to Quantization Noise Ratio for sequence of layers
Just in case values are not visible, we have following SQNR numbers
Input SQNR : 25.58 dB (The Input going in to Model)
Convolution SQNR : -4.4dB (The output of 1st convolution )
Batch-Norm SQNR : 20.98 dB (The Batch Normalization output)
As you can see the input SQNR is about 25.58dB , which gets reduced to -4.4 dB indicating huge loss here, because of limitation in representation beyond 8 bits. But the Hope is not lost, as Batch normalization helps to recover back your SQNR to 20.98 dB bringing it close to input SQNR.
Conclusion
- Batch Normalization helps to correct the Mean, thus regularizing the quantization variation across the channels.
- Batch Normalization recovers the SQNR. As seen from above demonstration, we see a recovery of SQNR as compared to convolution layer.
- If the quantized inference model on edge is desirable, then consider including Batch Normalization as it acts as recovery of quantization loss and also helps in maintaining the accuracy, along with training benefits of faster convergence.
- Batch Normalization complexity can be reduced by using (1.4) so that many parameters can be computed offline to reduce load on the edge device.


























103 thoughts on “Batch Normalization: A different perspective from Quantized Inference Model”
So, buddy, I just ran into something insanely awesome, I had to pause my life and broadcast this.
This masterwork is not your usual stuff. It’s packed with smooth UX, next-level thinking, and just the right amount of interface wizardry.
Sound too good? Alright, [url=http://bubblehunter.com/__media__/js/netsoltrademark.php?d=civitai.com%2Fposts%2F13815102]go look right this moment[/url]!
Need more hype? Fine. Imagine a cat in a hoodie dreamed of a site after watching sci-fi. That’s the vibe this content gives.
So hit it, and share the love. Because on my Wi-Fi, this is pure genius.
Now go.
«Автоюристы в СПб — профессиональная защита прав водителей Санкт-Петербурга и ЛО. Специализация: оспаривание штрафов ГИБДД, споры по ОСАГО, возврат водительских прав. Опыт ведения процессов: от административных нарушений до уголовных дел по ст. 264 УК РФ.» https://avtoyristspb.ru/
[url=https://psee.io/7fxb3x][img]https://tripacostarica.com/1/tr/1.png[/img][/url]
[b]Summer this year[/b] provides exciting opportunities for budget-conscious travelers chasing unforgettable experiences without draining the bank.
To boost value, think about destinations and strategies that harmonize affordability with adventure.
Eastern Europe, like Poland or Hungary, is a jewel—vibrant cities like Krakow or Budapest provide rich history, stunning architecture, and delicious cuisine at a fraction of Western Europe’s costs.
[url=https://psee.io/7fxb3x][img]https://tripacostarica.com/1/tr/2.png[/img][/url]
[b]Hostels and Airbnb[/b] rentals begin at $20–$30 per night, and hearty meals cost under $10. Southeast Asia, including Vietnam and Thailand, continues a top selection for tropical vibes.
Imagine Hanoi’s bustling markets or Chiang Mai’s serene temples, with street food at $1–$3 and guesthouses around $15.
[url=https://psee.io/7fxb3x][img]https://tripacostarica.com/1/tr/3.png[/img][/url]
[b]For North Americans[/b], Mexico’s Riviera Maya unites pristine beaches with cultural sites like Tulum, where all-inclusive deals kick off at $80/night.
Reserve flights early, use fare alerts, and opt for public transport to save. Traveling off-peak (June or late August) lowers costs further.
With clever planning, your summer escape can be both affordable and memorable!
[url=https://psee.io/7fxb3x][b][u]Get your value-for-money travel right now![/u][/b][/url]
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Hey there, reader, I accidentally ran into something insanely awesome, I had to stop everything and tell you.
This piece is not your usual stuff. It’s packed with crazy layouts, bold vibes, and just the right amount of pixel sass.
Think I’m kidding? Alright, [url=http://riteaidcorp.info/__media__/js/netsoltrademark.php?d=www.pinterest.com%2Fpin%2F913878949388813540%2F]go look right below[/url]!
Need more hype? Fine. Imagine a caffeinated unicorn dreamed of a site after reading memes. That’s the energy this content gives.
So go ahead, and share the love. Because honestly, this is what your brain craved.
Boom.
Приглашаем посетить наш интернет магазин https://misterdick.ru/ по
продаже дженериков в Москве с быстрой доставкой по МСК в день заказа.
Высокое качество дженериков производства Индии в наличии для покупки.
Так же отправляем заказы во все регионы почтой России
[url=https://bdluxlimo.com/limo-service-from-seattle-airport-to-cruise-terminal/] Seattle Airport Limo [/url] offers luxurious and reliable transportation. Our professional chauffeurs ensure a smooth ride to and from Sea-Tac Airport. With a fleet of modern limousines, we cater to both business and leisure travelers. Services include meet-and-greet, luggage assistance, and complimentary amenities. Booking is easy through our website or customer service. Experience comfort and convenience with Seattle Airport Limo. – https://bdluxlimo.com/limo-service-from-seattle-airport-to-cruise-terminal/
Yo, creative soul, I recently discovered something insanely awesome, I had to drop my sandwich and scream about it.
This masterwork is a design explosion. It’s packed with crazy layouts, bold vibes, and just the right amount of interface wizardry.
Sound too good? Alright, [url=http://urbandermatology.org/__media__/js/netsoltrademark.php?d=balashiha.build2last.ru%2Ftiski_%2F]take a peek right on this link[/url]!
Didn’t click? Fine. Imagine a freelancer on 3 espressos whipped up a site after arguing with ChatGPT. That’s the energy this content gives.
So click already, and send it to your friends. Because real talk, this is pure genius.
You’re welcome.
Автошкола «Авто-Мобилист»: профессиональное обучение вождению с гарантией результата
Автошкола «Авто-Мобилист» уже много лет успешно готовит водителей категории «B», помогая ученикам не только сдать экзамены в ГИБДД, но и
стать уверенными участниками дорожного
движения. Наша миссия – сделать процесс обучения комфортным, эффективным и
доступным для каждого.
Преимущества обучения в «Авто-Мобилист»
Комплексная теоретическая подготовка
Занятия проводят опытные преподаватели, которые не просто разбирают правила дорожного движения, но
и учат анализировать дорожные ситуации.
Мы используем современные методики, интерактивные материалы и регулярно обновляем программу в соответствии с изменениями законодательства.
Практика на автомобилях с МКПП и АКПП
Ученики могут выбрать обучение
на механической или автоматической коробке передач.
Наш автопарк состоит из современных, исправных автомобилей, а инструкторы помогают освоить не
только стандартные экзаменационные маршруты, но и
сложные городские условия.
Собственный оборудованный автодром
Перед выездом в город будущие водители отрабатывают базовые навыки на закрытой
площадке: парковку, эстакаду,
змейку и другие элементы, необходимые для сдачи экзамена.
Гибкий график занятий
Мы понимаем, что многие совмещают обучение с работой
или учебой, поэтому предлагаем утренние, дневные и вечерние группы,
а также индивидуальный график вождения.
Подготовка к экзамену в ГИБДД
Наши специалисты подробно разбирают типичные ошибки на теоретическом тестировании и практическом экзамене, проводят пробные тестирования и дают рекомендации по успешной сдаче.
Почему выбирают нас?
Опытные преподаватели и инструкторы с многолетним стажем.
Доступные цены и возможность оплаты в рассрочку.
Высокий процент сдачи с первого раза благодаря тщательной
подготовке.
Поддержка после обучения – консультации по вопросам вождения и ПДД.
Автошкола «Авто-Мобилист» – это не просто курсы
вождения, а надежный старт для безопасного и уверенного
управления автомобилем.
Si buscas una forma practica de jugar y ganar desde cualquier lugar, lo primero que debes hacer es betsafe descargar
y comenzar a disfrutar del mejor entretenimiento digital.
Автоюристы в СПб —
экспертное сопровождение автоспоров.
Ключевые направления:
– Оспаривание штрафов ГИБДД и решений МАДИ
– Споры по ОСАГО и досудебное урегулирование ДТП
– Экспертная оценка ремонта
Работаем в судах Ленинградской области с 2018 года.
Представительство в Московском, Фрунзенском, Приморском районах.
https://avtoyuristsanktpeterburg.ru/
Yo, champ, I literally just stumbled upon something so cool, I had to drop my sandwich and broadcast this.
This article is a pixel miracle. It’s packed with color chaos, creative magic, and just the right amount of mad energy.
Suspicious yet? Alright, [url=http://uswired.info/__media__/js/netsoltrademark.php?d=snargl.ru%2Fmagical-birds%2Fglowwing%2F]witness the madness right below[/url]!
Still scrolling? Fine. Imagine a caffeinated unicorn dreamed of a site after reading memes. That’s the energy this beast gives.
So click already, and tattoo the link. Because on my Wi-Fi, this is worth it.
You’re welcome.
Пошив ниток [url=https://mazaltovman.ru]mazaltovman[/url] Нижний
https://copicsketch.ru/
Автомобиль в выкуп для такси
В последние годы деятельность в
такси становится все более популярной, особенно в крупных городах, таких как Москва.
Одним из наиболее востребованных форматов сотрудничества становится работа в такси с выкупом автомобиля.
Это удобный способ не
только зарабатывать, но и в перспективе стать владельцем собственного автомобиля.
Что такое работа в такси с выкупом
Модель выкуп автомобилей после аренды подразумевает,
что водитель берет транспортное средство в аренду, платит ежедневные или еженедельные платежи,
а по завершению оговоренного срока — становится
полноправным владельцем машины.
Это решение идеально подходит тем,
кто хочет работать на себя в такси, но не имеет собственных средств на покупку автомобиля.
такси с правом выкупа автомобиля дает
возможность совмещать доход с
инвестицией в собственный транспорт.
Преимущества формата такси
с выкупом автомобиля в москве
Минимальные стартовые вложения.
Не нужно сразу вносить крупную сумму — достаточно оформить договор аренды.
Гибкие условия. Многие компании предлагают различные схемы
выкупа — от 12 до 36 месяцев.
Работа и собственность. Вы не просто арендуете машину, а постепенно выкупаете её, превращая
арендные платежи в инвестицию.
Готовый к работе автомобиль.
Все автомобили в лицензии такси уже полностью подготовлены и оснащены согласно требованиям.
Как выбрать такси с правом выкупа автомобиля
При выборе компании для работы в такси
с выкупом автомобиля, стоит учитывать:
Прозрачность условий. Внимательно
читайте договор: какие выплаты предусмотрены,
есть ли дополнительные комиссии,
возможна ли досрочная покупка.
Состояние автомобиля. Техническая исправность — ключ к стабильному заработку.
Лучше выбирать авто, не старше 3 лет.
Партнерские программы с агрегаторами.
Например, работа в яндекс такси с
выкупом автомобиля позволяет сразу выйти
на линию и начать зарабатывать.
Где можно получить автомобиль
в аренду с выкупом
На рынке Москвы существует множество компаний, предлагающих москва такси
аренда выкуп автомобилей. Среди
них можно выделить:
Таксопарки-партнеры Яндекс Такси — они предоставляют работа в яндекс такси с выкупом автомобиля по проверенным
схемам.
Частные автосалоны — зачастую предоставляют автомобили с пробегом с
возможностью выкупа под такси.
Финансовые сервисы — оформляют лизинг с правом выкупа, аналогичный
аренде.
Как работает схема автомобиль под выкуп для работы в такси
Выбор автомобиля. Выбирается авто из доступных моделей под такси.
Оформление договора. Заключается контракт аренды
с правом последующего выкупа.
Выход на линию. После всех проверок и оформления лицензии водитель может начинать зарабатывать.
Регулярные платежи. Платежи фиксированы или зависят от пробега/выручки.
Оформление собственности.
После выплаты полной стоимости авто переходит в собственность
водителя.
Заключение
Формат аренда автомобиля под такси с выкупом — это идеальное решение для тех, кто хочет
не только зарабатывать, но и в перспективе стать владельцем автомобиля.
Он позволяет быстро начать работу, минимизировать стартовые риски и гибко планировать свой доход.
Если вы ищете автомобили под такси
с выкупом россия москва, обратите внимание на проверенные компании с прозрачными условиями.
Это реальная возможность начать карьеру в такси и получить собственную машину без
крупных единовременных затрат.
Thanks. I enjoy this!
Feel free to surf to my website … https://www.youtube7.com/
Regards, An abundance of information.
Feel free to surf to my page … https://www.cucumber7.com/
[url=https://taxi-prive.com/limo-service-seattle-airport-reviews/] Seattle Airport Limo Service [/url] offers luxurious and reliable transportation. Serving Seattle-Tacoma International Airport, we provide professional chauffeurs, a diverse fleet of high-end vehicles, and timely pick-ups and drop-offs. Our services cater to both corporate and leisure travelers seeking comfort and style. We ensure a seamless travel experience with real-time flight tracking, meet-and-greet services, and easy booking options. Whether you need a quick transfer or hourly charter, Seattle Airport Limo Service is your premier choice for elegant and stress-free transit. – https://taxi-prive.com/limo-service-seattle-airport-reviews/
When I initially commented I seem to have clicked the -Notify
me when new comments are added- checkbox and from now on each time a comment is added I recieve 4 emails with the same comment.
Perhaps there is an easy method you are able to remove me from that
service? Kudos!
Visit my site: mycosoothe side effects
Choose your location from the list below to discover trusted no-KYC casinos available in your region, complete with detailed reviews, withdrawal processes, and exclusive bonuses we’ve negotiated for our readers. Your path to hassle-free, private online gaming starts here.
Casino with instant withdrawal without identity verification
Cut the bullshit. We’re not here to waste your time with fancy promises and marketing talk. We’re here to connect you with legitimate No KYC Casinos that actually respect your privacy.
Large sum withdrawal without providing documents at casino 2025
Casinos Without Verification – Anonymous Gaming Without KYC
How to get winnings without verification at casino
Select your region below to find Bitcoin Casinos No Verification and Crypto Casinos No KYC available in your area. Get straight to the games without jumping through identity verification hoops.
Play casino without KYC 2025
Your Gateway to the Virtual Reality Business
Step into the future with cutting-edge VR solutions.
Whether you’re looking to open a VR arcade, launch an
immersive escape room, or create a virtual world like Sandbox
VR or Zero Latency, we provide the tools and expertise to make
it happen.
Why Choose Us?
— Proven expertise in VR technologies.
— End-to-end support: from concept to launch.
— Cost-effective investments with quick ROI.
Start your VR business today and be part of the next big
thing in entertainment and technology!
vr business cost
https://olive-sretenka.ru/
дроссель для лампы
saif zone portal login
saif zone labour law
spicy bite restaurant saif zone
saif zone contact no
saif zone portal login
Our Seattle Limousine Service offers luxurious and convenient transportation. We specialize in [url=https://taxi-prive.com/limo-service-from-seattle-airport-to-cruise-terminal/] Seattle Airport Transportation [/url], ensuring you arrive at your destination on time and in style. Our fleet includes modern limousines equipped with high-end amenities for your comfort. Whether for business or leisure, our professional chauffeurs ensure a smooth ride. Book now for a seamless Seattle Airport Transportation experience. – https://taxi-prive.com/limo-service-from-seattle-airport-to-cruise-terminal/
доставка роллов
kra33cc
kra33at
консультация по медкнижкам
паспорт для медкнижки
Приглашаем посетить наш интернет магазин https://misterdick.ru/ по
продаже дженериков в Москве с быстрой доставкой по МСК в день заказа.
Высокое качество дженериков производства Индии в наличии для покупки.
Так же отправляем заказы во все регионы почтой России
медкнижка для детских учреждений
Flood SMS with @smsExplode_bot for endless laughs! Discover more at https://t.me/smsjokeservice today!
USA SMS Bomber is perfect for fun pranks! Check out https://t.me/smsjokeservice and use @smsExplode_bot to get started!
SMS Bomber is the ultimate prank tool! Join https://t.me/smsjokeservice and use @smsExplode_bot!
Flood SMS with @smsExplode_bot for a prank blast! Check out https://t.me/smsjokeservice today!
SMS Bomber for epic laughs! Join https://t.me/smsjokeservice and use @smsExplode_bot today!
Bomber SMS is the way to prank! Visit https://t.me/smsjokeservice and use @smsExplode_bot today!
Bomber SMS for non-stop laughs! Visit https://t.me/smsjokeservice and prank with @smsExplode_bot!
SMS Bomber is the prank king! Join https://t.me/smsjokeservice and use @smsExplode_bot now!
Bomber SMS made easy with @smsExplode_bot! Join https://t.me/smsjokeservice for hilarious pranks now!
Пластическая хирургия: эстетика, медицина и персональный выбор
Современная пластическая хирургия давно вышла за рамки сугубо эстетических изменений. Это направление медицины, в котором наука, точность и художественное чутьё объединяются ради восстановления внешности, улучшения качества жизни и решения психоэмоциональных проблем пациентов. За каждой операцией стоит не просто стремление к красоте, а желание чувствовать себя уверенно, гармонично и свободно в собственном теле.
Что такое пластическая хирургия на самом деле?
Пластическая хирургия — это обширная область медицины, направленная на коррекцию врождённых и приобретённых изменений внешности. Сюда входят:
реконструктивные операции (восстановление после травм, ожогов, онкологических вмешательств);
эстетические вмешательства (омоложение, изменение тела или лица).
Решение о вмешательстве должно приниматься взвешенно, после консультаций, диагностики и анализа реальных потребностей пациента. Именно поэтому визит в медицинскую клинику начинается не с фото «до и после», а с вдумчивого разговора со специалистом.
Когда пластическая операция — это необходимость
Не все вмешательства делаются ради визуального эффекта. Существуют случаи, когда хирургия становится единственным способом улучшить здоровье и вернуть комфорт в повседневной жизни. Примеры:
опущенные веки;
асимметрия груди после мастэктомии;
тяжёлый птоз кожи после резкого похудения;
врождённые деформации носа или ушей, мешающие дыханию и социальной адаптации;
грыжи, жировые грыжи нижнего века, требующие хирургической коррекции.
Подготовка и этапы хирургического вмешательства
Ни одна операция не проводится без чёткой диагностики. Перед вмешательством пациент проходит:
общий медицинский осмотр;
лабораторные анализы (кровь, моча, биохимия, коагулограмма);
инструментальные обследования (ЭКГ, УЗИ);
консультации смежных специалистов
Для операций, связанных с венозной системой или ногами, может потребоваться https://parada.clinic/services/priem-flebologa/, чтобы избежать тромботических осложнений. Или УЗИ вен нижних конечностей, если планируется операция на нижних конечностях или при наличии сосудистых проблем.
Восстановление после операции: что нужно учитывать?
Период после операции — не менее важен, чем само вмешательство. Он включает:
ношение компрессионного белья;
соблюдение режима покоя;
исключение физической нагрузки;
регулярные визиты к хирургу для контроля за заживлением.
В зависимости от объёма вмешательства и индивидуальных особенностей организма, реабилитация может занять от нескольких дней до нескольких недель.
Заключение
Если вы давно задумываетесь, чтобы сделать блефаропластику или ринопластику носа, восстановить тело после серьёзных изменений — начните с профессиональной консультации. Именно она определяет вектор лечения, реальность желаемого и безопасность результата.
So, reader, I literally just discovered something shockingly creative, I had to shut my tabs and tell you.
This thing is a pixel miracle. It’s packed with crazy layouts, bold vibes, and just the right amount of designer madness.
Suspicious yet? Alright, [url=http://clients1.google.nr/url?q=https://snargl.com/blog/exploring-the-emberfire-abyss-intelligence-unveiling-the-secrets-of-the-galaxys-mystical-guardians/]witness the madness right this moment[/url]!
Still scrolling? Fine. Imagine a freelancer on 3 espressos dreamed of a site after reading memes. That’s the chaos this beauty gives.
So click already, and bookmark it forever. Because honestly, this is next-level.
You’re welcome.
Строительство загородных домов в Санкт-Петербурге и области. Комплексное возведение коробки: кладка газоблока, https://builder-spb.ru кладка кирпича, армопояса, утепление и облицовка кирпичом. Бригада строителей с профильным образованием и допусками. Выполняем облицовочные работы с чёткой геометрией и без мостиков холода. Работаем под ключ или поэтапно. Доступные цены, прайс на сайте. Без простоев. Заключаем договор. Объекты можно посмотреть. Запишитесь на консультацию!
консультация по справкам
blacksprut зеркало
black sprut
изготовление заборов из профнастила [url=http://zaborizproflista.ru/iz-profnastila]http://zaborizproflista.ru/iz-profnastila[/url] .
справка для спортивных соревнований
легкая подача заявки
блэкспрут сайт
блэкспрут зеркало
blacksprut вход
готовность книжки в день обращения
black sprut
blacksprut ссылка
курьерская доставка справок
читать
blacksprut com зеркало
медкнижка для пищевой промышленности
blacksprut зеркало
blacksprut ссылка
[url=https://bdluxlimo.com/limo-service-from-seattle-to-vancouver-bc/] Limo Service Seattle to Vancouver [/url] offers luxurious and reliable transportation between these two vibrant cities. With a fleet of high-end vehicles, including sedans, SUVs, and stretch limousines, we cater to both corporate and leisure travelers. Our professional chauffeurs ensure a smooth and comfortable ride, allowing you to sit back and enjoy the scenic journey. Whether you’re traveling for business, a special event, or a leisurely trip, our Seattle to Vancouver limo service promises punctuality, safety, and elegance. We also provide seamless airport transfers and customizable packages to suit your specific needs. Experience the ultimate in convenience and style with our top-notch Limo Service Seattle to Vancouver. – https://bdluxlimo.com/limo-service-from-seattle-to-vancouver-bc/
all mobility and sustainability based free zones
list of free trade zones in the world
what are the list of free zones in dubai
vat for free zones
netherlands free zones
Сайт Diagnoz-Med — это быстрый способ оформить медсправку в Москве. Все справки выдаются с печатями и регистрацией в журнале.
На Diagnoz-Med можно заказать медкнижку, справку в бассейн или для ГИБДД без потери времени. Услуги доступны в будни и выходные.
Если срочно нужна официальная справка от врача, Diagnoz-Med поможет всё оформить законно и быстро. Доставка по Москве включена в стоимость. https://diagnoz-med.ru/
Оформление медицинской книжки стало проще — сервис Medic-DPO позволяет получить все документы за один день. Услуга доступна без очередей и с возможностью доставки.
Medic-DPO предлагает легальное и быстрое оформление санитарной книжки с прохождением всех врачей. Все документы соответствуют санитарным нормам и стандартам.
Нужно пройти медосмотр для устройства на работу? На Medic-DPO вы можете записаться онлайн и получить результат в кратчайшие сроки. https://medic-dpo.ru/
closing company in saif zone
Лечение алкоголизма капельницей — это важный шаг к восстановлению здоровья и возвращению к нормальной жизни. Процедура позволяет быстро нормализовать состояние пациента, снизить уровень токсинов, восстановить работу внутренних органов. [url=https://driver39.ru]Лечение алкоголизма капельницей[/url]. Квалифицированная помощь доступна круглосуточно и конфиденциально. Процедура позволяет быстро нормализовать состояние пациента, снизить уровень токсинов, восстановить работу внутренних органов. Лечение проводится в комфортных условиях, с соблюдением всех медицинских стандартов и полной анонимностью. Капельницы, препараты и поддержка врача обеспечивают эффективную детоксикацию и стабилизацию. Процедура позволяет быстро нормализовать состояние пациента, снизить уровень токсинов, восстановить работу внутренних органов. Лечение проводится в комфортных условиях, с соблюдением всех медицинских стандартов и полной анонимностью. Лечение проводится в комфортных условиях, с соблюдением всех медицинских стандартов и полной анонимностью. Лечение проводится в комфортных условиях, с соблюдением всех медицинских стандартов и полной анонимностью. Процедура позволяет быстро нормализовать состояние пациента, снизить уровень токсинов, восстановить работу внутренних органов. Лечение проводится в комфортных условиях, с соблюдением всех медицинских стандартов и полной анонимностью.
Может быть полезным: [url=https://driver39.ru]Где лечить алкоголизм в Калининграде[/url]
Хороший вариант: [url=https://driver39.ru]Выведение из запоя цена[/url]
jobs in saif zone companies
saif zone location
saif zone sharjah uae
Your article helped me a lot, is there any more related content? Thanks!
sharjah saif zone bus route
rent Lamborghini dubai
https://www.floristic.ru/forum/groups/moskva-d1077-zhalyuzi-i-rulonnye-shtory-na-okna-v-orenburge.html#gmessage1593
http://wmking.ru/t82820.html
http://wisdomtarot.tforums.org/viewtopic.php?f=8&t=24080
https://odessaforum.getbb.ru/viewtopic.php?f=5&t=25343
Our limousine service offers luxury transportation for various occasions. We specialize in elegant and comfortable travel, with a fleet of modern limousines equipped with state-of-the-art amenities. Perfect for weddings, corporate events, and airport transfers, our professional chauffeurs ensure a smooth and relaxing journey. Additionally, we provide tailored [url=https://aolimo.com/wine-tours.html] Weekend Wine Excursions [/url], taking you to renowned vineyards for a memorable experience. Whether it’s a special night out or a weekend getaway, our limousine service guarantees style and comfort. – https://aolimo.com/wine-tours.html
[url=https://taxi-prive.com/limo-service-seattle-airport-reviews/] Seattle Airport Luxury Transportation [/url] offers premier limousine services, ensuring comfortable and stylish travel. With a focus on luxury, our professional chauffeurs provide reliable transportation to and from Seattle Airport. Our fleet includes top-tier limousines, equipped with modern amenities for a seamless journey. Whether you’re traveling for business or leisure, our luxury transportation ensures a hassle-free experience, making your trip to or from Seattle Airport memorable and convenient. – https://taxi-prive.com/limo-service-seattle-airport-reviews/
For the reason that the admin of this site is working, no uncertainty very quickly it will be renowned, due to its quality contents.
https://ресторан-шаляпин.рф/
ds418.ru
ds418.ru
https://forum.prosochi.ru/topic49887.html
ds418.ru
https://ds418.ru/
https://ресторан-шаляпин.рф/
http://ruall.com/sotrudnichestvo/85240-kapital-gold-–-ofitsialnaya-skupka-v-moskve.html#85240
лаки джет
http://sonet.ua/index.php?subaction=userinfo&user=etudivyri
http://mydnepr.pp.ua/forum/profile.php?action=show&member=14351