
In the last 40 years, more than 22,000 people were killed at U.S. railroad crossings*. But data shows that railroad crossings have become safer over time, thanks to the installation of gates and lights at more crossings, timed traffic signals and increased public education efforts. Helping further with these efforts are several noted companies and startups which are using technology such as the adoption of computer vision applications based on Machine learning techniques and artificial neural networks to tackle this problem.
This article describes AI powered railroad crossing detection, a critical application that is associated with improving track safety.

RailRoad Crossings
A railroad intersection is where a roadway crosses railroad tracks at the same level. This term also applies when a rail line with a separate right-of-way or reserved track crosses a road. Other names for railroad intersections are railway level crossing, grade crossing, road through railroad, criss-cross, railroad crossing, train crossing etc. An overview of railroad intersections will be found here Railroad Intersection.

Road Detection
Many methods are used for road, lane and rail detection, using both image processing [Image Processing on Road Detection] and deep learning based techniques [Road detection based on simultaneous deep learning approaches]. However, no single solution is mentioned to be applicable in this circumstance of mixed scenario of rail and road. So, one way to address this use case is to have a single technique, which can efficiently detect the rail portions in the railroad crossings.

Data Preparation
Data preparation is the process of cleaning and transforming raw data prior to processing and analysis. It is an important step prior to processing and often involves labelling data, reformatting data, making corrections to data and the combining of data sets to enrich data. In this case, the data is collected by dumping frames from several rail videos. Then the road portions within the region of interest (ROI) are labelled using a labelling tool. Several labelling tools are available which can be utilized for this purpose. The details regarding one such labelling tool can be found here [LabelMe].
Semantic Segmentation
Semantic segmentation is the task of classifying pixels in the image to a predefined class. Semantic Segmentation has many applications, such as detecting road signs, detecting drivable areas in autonomous vehicles etc. An overview of keras semantic segmentation can be found at these sources – Semantic Segmentation and A Beginner’s guide to Deep Learning based Semantic Segmentation using Keras.
Semantic segmentation network follows an encoder decoder architecture. So the initial step is to choose an appropriate encoder and decoder network as per our problem definition. A standard model such as ResNet, VGG or MobileNet is chosen for the base network usually. When the model is trained for the task of semantic segmentation, the encoder outputs a tensor containing information about the objects, and its shape and size. The decoder takes this information and produces the segmentation maps. A detailed explanation regarding various model architectures for semantic segmentation networks can be found here – A Simple Guide to Semantic Segmentation.
Once the base network is chosen, we need to choose appropriate segmentation architecture. Several segmentation architectures are available for semantic segmentation such as FCN, SegNet, UNet and PSPNet.
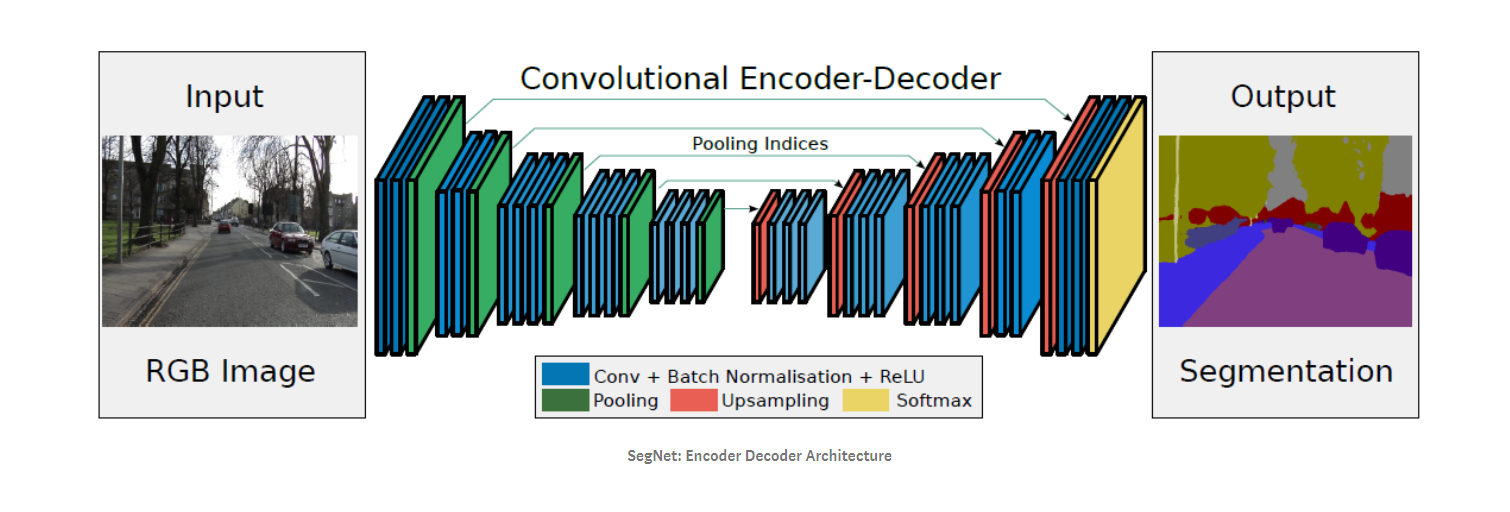
SegNet:
SegNet follows an encoder decoder architecture. The encoder has 13 convolutional layers from VGG-16. While doing 2×2 max pooling, the corresponding max pooling indices are stored. And the decoder uses this to perform non-linear upsampling.

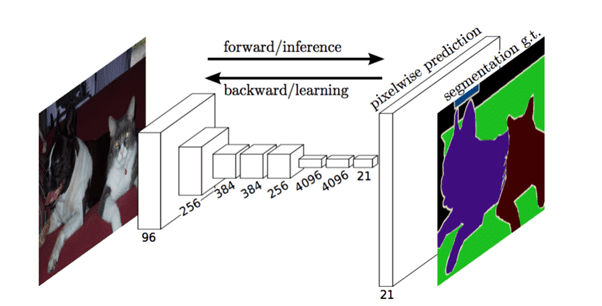
FCN (Fully Convolutional Network) :
The FCN network is an extension of CNN. In normal CNN, we cannot take arbitrary-sized images. This limitation is overcome in FCN; FCNs only have convolutional and pooling layers which give them the ability to make predictions on arbitrary-sized inputs.The three variants are FCN8, FCN16 and FCN32. In FCN8 and FCN16, skip connections are used. More information regarding FCN network can be found here – Fully Convolutional Network.
Implementation
We use Keras library for training and testing the semantic segmentation network. Keras segmentation has all the utilities required for that.
Generating ROI
We are focussing the detections within a region of interest. An ROI can be drawn by mouse interaction and opencv functionalities and then applying a four point transform on the image. Label the concrete portions in the road rail intersection areas within the ROI using LabelMe as mentioned earlier. LabelMe generates json files corresponding to annotations.
Training and Testing
Using the annotated jsons from LabelMe, corresponding mask images are generated and these mask images are used for further training. Several pretrained encoder-decoder networks like resnet50_segnet, mobilenet_unet, resnet50_unet etc. are available, which we can choose based on the requirement. Our custom base model will efficiently generate feature vectors from these mask images and these features are given to our custom decoder network for result vector generation. While testing using our custom model, the output will be a mask corresponding to road portions and these predicted mask images can be mapped to our original image using opencv functionalities.
Accuracy
Our custom semantic segmentation network efficiently detects the road portions in the railroad intersections with an accuracy of 99%.
Conclusion
The system described will efficiently detect the road portions in the railroad intersections areas. Our obtained results are very promising in terms of detection rate and also have less inference time. As rail networks expand across the globe, the number of intersections, junctions, and level crossings increase, resulting in potential safety hazards. The AI-based module presented in this blog can help improve rail crossing safety.


























{kind=link}
{kind=link}
46 thoughts on “Computer Vision and AI-based Railroad Crossing Detection”
LIMITED-TIME DEAL: ChatGPT PLUS/PRO at the LOWEST PRICE online!
GRAB YOUR SUBSCRIPTION NOW: ❣️ [url=https://bit.ly/UNLOCK-ChatGPT-PRO]ChatGPT PLUS/PRO[/url] ❣️
✅ WHY CHOOSE US?
✔ Instant activation – No waiting!
✔ Official subscription – No risk of bans!
✔ Cheaper than OpenAI’s website!
✔ Thousands of happy customers & 5-star reviews!
✔ 24/7 support – We’re here to help!
✅ HOW TO ORDER? (FAST & EASY!)
1️⃣ Click the link & select your plan.
2️⃣ Pay securely (Crypto, PayPal, Cards, etc.).
3️⃣ Receive your login OR unique activation code instantly!
4️⃣ Enjoy ChatGPT PLUS/PRO in minutes!
✅ WHAT’S INCLUDED?
⭐ GPT-4o (Fastest & Smartest AI!)
⭐ GPT-4 Turbo (Longer, detailed answers!)
⭐ Advanced AI features (Code Interpreter, Plugins, File Uploads!)
⭐ Priority access – No more downtime!
⚠ DON’T PAY FULL PRICE! Get ChatGPT PRO cheaper HERE:
❣️ [url=https://bit.ly/UNLOCK-ChatGPT-PRO]ChatGPT PLUS/PRO[/url] ❣️
⏳ DEAL ENDS SOON! Prices are rising—CLAIM YOUR SPOT NOW!
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
ordonnance perime: PharmaDirecte – pyralvex solution
puis-je me faire vacciner en pharmacie sans ordonnance ?: PharmaDirecte – a derma pain surgras
online medicijnen kopen zonder recept: apotheek webshop – verzorgingsproducten apotheek
apotheek online nederland: apothekers – holandia apteka internetowa
https://tryggmed.com/# forstoppelse apotek
http://zorgpakket.com/# medicijnen online kopen
24/7 apotek: apotek sykehuset – sjekk av fГёflekker apotek
apoktek: ta vaksine apotek – halstabletter apotek
https://tryggmed.com/# l-serin på apotek
sopp i navlen apotek [url=http://tryggmed.com/#]klotrimazol apotek[/url] tudca apotek
flass shampoo apotek: TryggMed – angrepille apotek
https://tryggmed.shop/# kompresjons bh apotek
leie brystpumpe apotek: TryggMed – covid vaksine pГҐ apotek
https://tryggmed.com/# fingerstГёtte apotek
beige hårfärg [url=http://snabbapoteket.com/#]Snabb Apoteket[/url] billiga ägglossningstest
e-recept apotek: Snabb Apoteket – omega 3 apotek
https://tryggmed.shop/# аптека норвегиÑ
bindor 100 pack: billiga dregglisar – bestГ¤lla lГ¤kemedel
hjemmetest kjГёnnssykdommer apotek [url=https://tryggmed.shop/#]TryggMed[/url] knestГёtte apotek
covidtest apotek: kolla mina recept – boka fransar
http://tryggmed.com/# urin stix apotek
allergivennlig mascara apotek: TryggMed – glidemiddel apotek
https://zorgpakket.shop/# apotheek kopen
preparat läkemedel [url=https://snabbapoteket.shop/#]får katter mens[/url] receptbelagda värktabletter mot ryggvärk
betakaroten apotek: bind etter fГёdsel apotek – kompress apotek
https://tryggmed.com/# tannkrem apotek
tatoveringskrem apotek: apotek pГҐ nettet – hurtigtest apotek
online pharmacy netherlands [url=https://zorgpakket.com/#]Medicijn Punt[/url] online pharmacy netherlands
varmepute med ris apotek: TryggMed – avfГёringstabletter apotek
http://tryggmed.com/# bomullshansker apotek
p piller apotek: SnabbApoteket – bГ¤sta ashwagandha
https://indiamedshub.com/# indian pharmacy
buy from mexico pharmacy: MediMexicoRx – safe mexican online pharmacy
https://medimexicorx.com/# reputable mexican pharmacies online
tadalafil mexico pharmacy [url=https://medimexicorx.com/#]MediMexicoRx[/url] legit mexican pharmacy without prescription
top 10 pharmacies in india: indian pharmacy online – Online medicine home delivery
https://expresscarerx.online/# ExpressCareRx
buy from mexico pharmacy: п»їmexican pharmacy – amoxicillin mexico online pharmacy
legit mexico pharmacy shipping to USA [url=https://medimexicorx.shop/#]MediMexicoRx[/url] order from mexican pharmacy online
https://medimexicorx.com/# mexican mail order pharmacies
reputable indian pharmacies: IndiaMedsHub – online pharmacy india
https://expresscarerx.org/# meloxicam pharmacy