
1. Introduction
Video is a common data input in the field of Computer Vision & Image processing. For example, in applications such as infrastructure maintenance and defect detection, video is captured from a camera source mounted on a drone or a locomotive. The captured data passes through a software pipeline where numerous operations such as image transformations, ML (Machine Learning) inference and tracking are performed.
Video processing can be seen as a sequence of operations done repeatedly for each frame. Such a serial process is easy to implement, but not practical in most cases due to low performance. To make the processing faster and to keep the accuracy high, the optimum solution is to come up with a procedure that will allow the processing steps to run simultaneously. Here, high volume video data is taken and split into a number of smaller videos called chunks and processed in parallel.
2. Celery task queue
Celery is a distributed task queue with focus on real-time processing and task scheduling. Celery systems can consist of multiple workers and brokers, which leads to horizontal scaling and high availability. Using the in-built ‘pool’ option, Celery tasks can be run asynchronously.
Documentation on Celery workers can be found here.
You can read more on Celery in the following 2 Ignitarium blogs:
- Use of Celery in Serverless systems for scaling AI workloads
- A Hands-on Guide to Backend Performance Optimization of a SaaS platform for scalable AI workloads.
In the subsequent sections, we’ll describe the use of Celery to manage the processing of video chunks.
3. Chunk processing
Before deep diving, let’s have clarity on chunks, and why we need it. After all, video is a sequence of frames captured and displayed at a given frame rate (FPS). Suppose we have enough compute servers in a cluster and our pipeline is set up for running inference, one simple method is to capture images, send them to each server asynchronously and wait for results. What are we missing here? There might be a relation between the current frame and a previous frame or a set of previous frames. Sending each image to servers individually means we are losing this valuable relation. For example, for tracking applications, it’s important to rely upon previous inference results to take a decision on current inference. This is exactly why we need chunk processing.
A chunk is a minimal representation of the original video. It should have all the properties of the original input video, ensuring that the previous information is not lost while calling the inference pipeline.
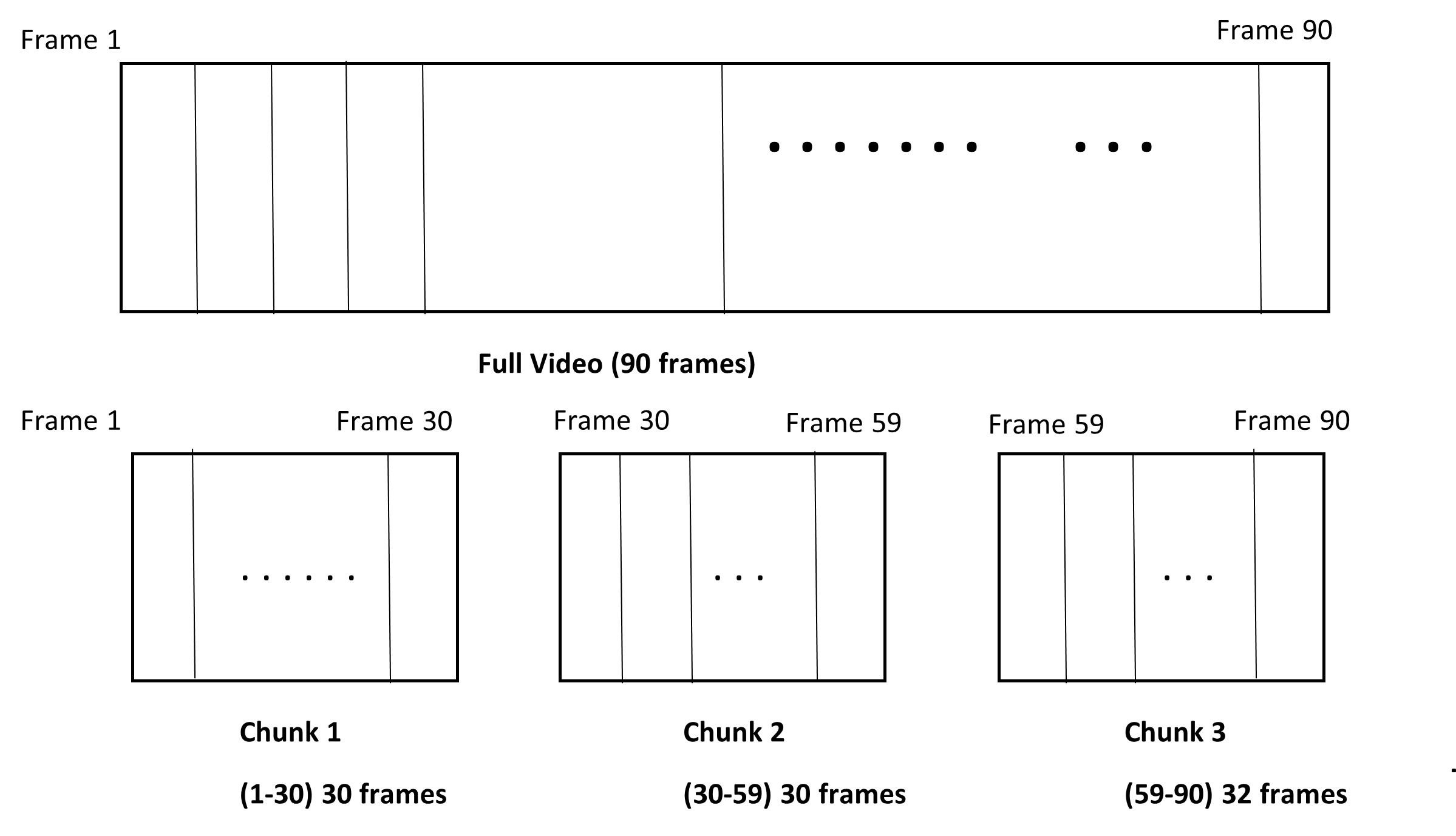
In the example shown in Fig 1., an input video of 90 frames is split into 3 chunks. A fixed chunk size of 30 is selected with 1 overlapping frame across chunks. Note that the first chunk will not have an initial overlapping frame. Similarly, the last chunk has 32 frames and not the ‘fixed’ chunk size of 30 frames; this is because there are no more chunks after this one. The last chunk will have a size equal to the defined fixed chunk size plus the remaining frames for that video.
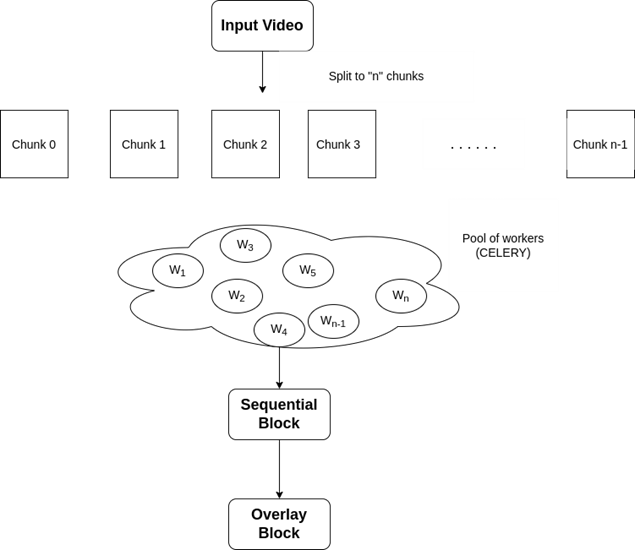
Fig 2. describes the overall workflow, where the input video is split into “n” number of chunks, each having a fixed chunk size.
W1, W2, W3, …. Wn represents different Celery workers that process these chunks.
The main components in the pipeline are:
- Broker:
- Used for storing tasks. The default Celery broker is RabbitMQ
- Backend:
- Stores results of task executions. Preferred Celery backend is Redis
- Worker:
- Process that runs on CPU or GPU and executes task from the task queue
3.1 Concurrency factor
Concurrency refers to the number of worker processes/threads. By default, multiprocessing is used to perform concurrent execution of tasks and concurrency defaults to the number of CPUs available on the machine.
- Concurrency can be set to high (4-8) for a relatively faster server.
- Concurrency should be lower (~1) for relatively slower servers.
- These worker configurations can be done at the time of worker bring-up.
3.2 Network File System (NFS)
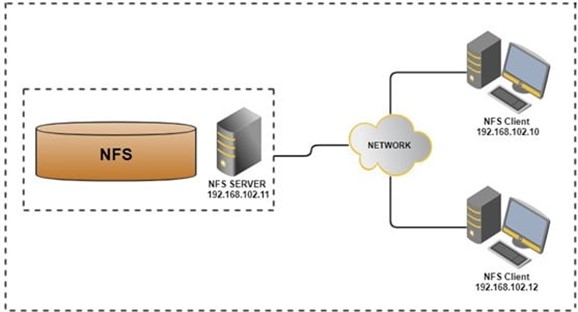
- NFS is a distributed file system protocol which allows you to mount remote directories on a server.
- Storage space is managed in a central location with writes to this central storage occurring from multiple clients.
All the machines in a cluster will use NFS. The input video to be processed will be stored on the shared NFS disk and will be accessible to all servers in the cluster. Chunks from this input video will be processed by workers within the cluster with temporary chunk results being written to the NFS-mounted shared space. For example, Chunk1 might be processed by Worker 1 (running on physical server 1) while Chunk 4 might be processed by Worker 4 (running on physical server 4).
3.3 Sequential Block
The Sequential block (Fig 2.) takes the results (video and other tracking results) from each chunk and generates a combined results video. This sequential block should not become a bottleneck in the entire pipeline. So, all the computationally expensive processes are performed by the pool of workers. The Sequential block just waits for the results to be generated by the worker pool and uses their references as input and then combines them sequentially to generate a single video. Per frame annotations on a global scale (w.r.t full video) will be stored in a dictionary (global dictionary).
3.4 Overlay Block
The Overlay module operates on chunks; for each chunk, this module will set the correct index to the global dictionary in order to extract the relevant annotations for a particular frame. The extracted information (eg. unique tile id on a rail track) will be overlayed on the video in such a manner that allows playback of either the entire video with all results annotated or only selected sections of the input video with its corresponding annotations.
4. Analysis
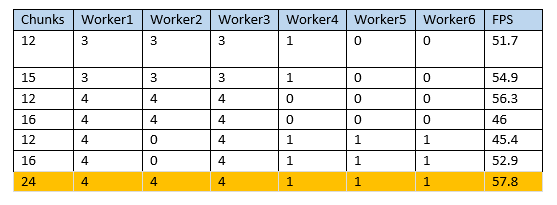
Table 1 describes the observations while running the pipeline on a full-length video (1800 frames) file.
- Each worker has been configured with custom concurrency values
- Adding more workers to the cluster improves overall FPS
- Increasing the number of chunks improves overall FPS
- Setting low concurrency to the slow speed workers improved overall FPS
5. Summary
Designing video processing pipelines at scale requires careful planning and proper testing. Instead of processing an entire video sequentially, chunk processing has significant benefits. Queue-based asynchronous methods like Celery is one of the best choices to consider for such use cases. Celery provides advanced features like autoscale, which can be leveraged to get maximum throughput and stability. This article described chunk based parallel processing of a single input video. This method of chunk processing is of even greater relevance when multiple input videos of large frame count are to be processed maintaining high processing throughput.

























