
System-on-chip (SoC) designs solve challenging design problems in different application domains by integrating diverse domain expertise. The successful design of such complex single-chip applications requires expertise in several technology areas such as communication, multimedia, encryption, and analog and RF designs. These technologies are increasingly hard to find in a single design house. Hence, there is a business model where the specialists in the specific domain provide the IP, and the SoC designer focuses on the system integration design aspects. Success will rely on using appropriate design and process technologies and the ability to interconnect existing components reliably in a plug-and-play fashion. SoC design methodologies are hence shifting from computation-centric to communication-centric ones. The design of the SoC interconnect thus demands significant research to ensure optimal communication between the components.
Evolution Of Interconnects
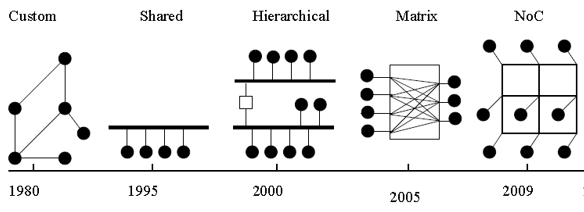
Shared buses such as ARM’s AMBA bus and IBM’s CoreConnect are the commonly used communication mechanisms in SoCs. They support a modular design approach that uses standard interfaces and allows for IP reuse, but shared bus structure becomes a performance bottleneck as the system bandwidth requirements scale-up.
Hierarchical Bus would involve using multiple buses or bus segments to alleviate the load on the main bus. This hierarchical structure would allow for local communication between modules on the same bus segment without causing congestion to the rest of the bus. The disadvantages to this approach are its reduced flexibility and scalability and its complication of the design process. The more cores are attached to the bus, the harder it is to accomplish time-closure and quality-of-service.
Bus Matrix, a full crossbar system is an alternative for on-chip bus communication. Still, as the number of participating systems rises, the complexity of wires could be dominant over the logic part. Also, these interconnect logic do not decouple activities generally classified as transport, transaction, and physical layer. Hence when we need any system upgrade, the interface design is affected, and all connected blocks are affected. Even though computation and storage benefit from the sub-micron technology uses smaller logic cells and memory, the energy for communication is not scaling down. Instead, the crosstalk effects, electromigration, and interconnect delay are affecting timing closure negatively.
Thus, in the early 2000s some authors proposed the use of a pre-defined platform to implement the communication among the several cores in a chip [2][3][4]. Such a platform is implemented as an integrated switching network, called Network-on-Chip (NoC), and meets some of the key requirements of future systems: reusability, scalable bandwidth, and low power consumption. Many analytical studies happened in this concept to quantize the advantage of switching to a network instead of wires.

NoC
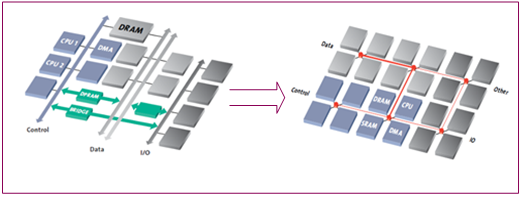
NoC replaces the ad-hoc global wire connections across a chip with intelligent network infrastructure. Models, techniques, and tools from the network are applied to SoC design with proper customization. Wire communication is changed to packet communication. Figure 2 below gives a high-level view of the shift in SoC architecture while moving from shared bus to network-based topology.
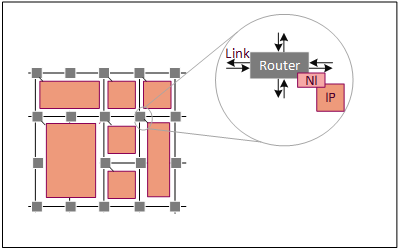
Building Blocks of NoC
A network-on-chip is composed of three main building blocks.
- The first and most important ones are the links that physically connect the nodes and implement the communication.
- The second block is the router, which implements the communication protocol.
- The last building block is the network adapter (NA) or network interface (NI). This block makes the logical connection between the IP cores and the network [6].
Link
A communication link is composed of a set of wires and connects two routers in the network. Links may consist of one or more logical or physical channels, and each channel is composed of a set of wires. The implementation of a link includes the definition of the synchronization protocol between source and target nodes. This protocol can be implemented by dedicated wires set during the communication or through other approaches such as FIFOs.
Routers
NoC router comprises a number of input ports, a number of output ports, a switching matrix connecting the input ports to the output ports, and a local port to access the IP core connected to this router. The router also contains a logic block that implements the flow control policies (routing, arbiter, etc.) and defines the overall strategy for moving data through the NoC.
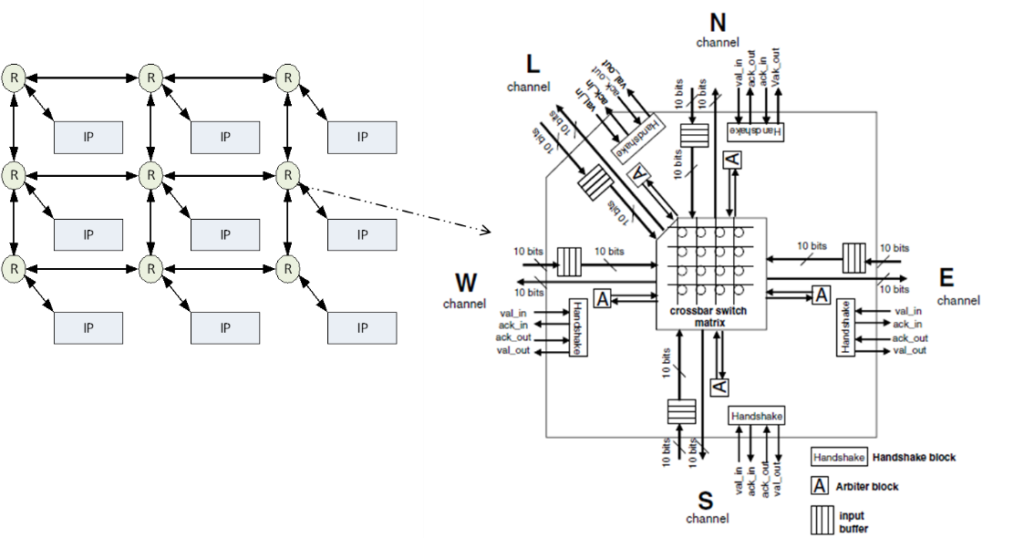
The primary design aspects of a router include:
- Flow Control – Characterizes packet movement in NoC, both global and local. The communication performance and the Quality of Service are guaranteed by the control logic. The control can be centralized or distributed. In centralized control, routing decisions are made globally and applied to all nodes, with a strategy that guarantees no traffic contention. This requires that all nodes share a common sense of time. In the distributed control, each router makes decisions locally.
- Routing Algorithm – Logic that selects one output port to forward a packet that arrives at the input port. There is deterministic and adaptive routing. For instance, in a deterministic routing, a packet always uses the same path between two specific nodes. In adaptive routing, alternative paths between two nodes may be used if the original path or a local link is congested.
- Arbitration Logic – While the routing algorithm selects an output port for a packet, the arbitration logic implemented in the router selects one input port when multiple packets.
- Buffering – The Buffering policy is the strategy used to store information in the router when there is congestion in the network, and a packet cannot be forwarded right away.
- Switching – The switching defines how the data is transmitted from the source node to the target one. In the circuit switching approach, the whole path (including routers and channels) from source to node is previously established (by the header) and reserved for the transmission of the whole packet. The payload is not sent until the whole path has been reserved. This can increase latency, but once the path is defined, this approach can give some guaranteed throughput, for example. In the packet-based switching approach on the other hand, all flits of the packet are sent as the header establishes the connection between routers.
Network Interface
This block makes the logic connection between the IP cores and the network, since each IP may have a distinct interface protocol with respect to the network. This block is important because it allows the separation between computation and communication. This allows the reuse of both core and communication infrastructure independent of each other.
The adapter can be divided into two parts:
- A front end manages the core requests and is ideally unaware of the NoC. This part is usually implemented as a socket – OCP (OCPIP 2011), VCI (VSI Alliance 2011), AXI (ARM 2011), DTL (Philips Semiconductors 2002), etc.
- A back end handles the network protocol (assembles and disassembles the packet, reorders buffers, implements synchronization protocols, helps the router in storage, etc.).
NoC Topology
NoC can be characterized by the structure of the routers connections. This structure or organization is called Topology and is represented by a graph G(N,C) where N is the set of routers and C is the set of communication channels.
The routers can be connected in Direct or Indirect topology.
- In the Direct topology, each router is associated to a processor and this pair can be seen as a single element in the system (so-called a node in the network). In this topology, each node is directly connected to a fixed number of neighbour nodes, and a message between two nodes goes through one or more intermediate nodes. The most common direct topologies are the n-dimensional grid or mesh, torus (or k-ary n-cube), and the hypercube shown in Figure.
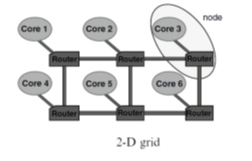
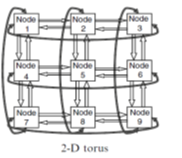
Figure 5: Direct Topology
- In an Indirect topology, not all routers are connected to processing units as in the direct model. Instead, some routers are used only to propagate the messages through the network, while other routers are connected to the logic, and only those can be the source and / or target of a message. Figure below shows the example of two such network topologies.
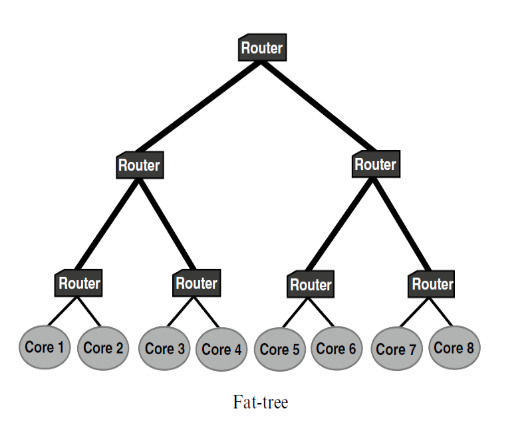
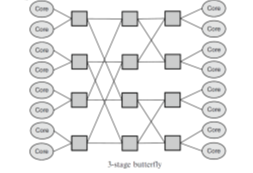
Fig 6: Indirect Topology

NoC Design Flow
The FlexNoC design flow follows a top-down approach where we start with specification and end up on optimized architecture after an iterative process [7][8], as shown in Figure 7.
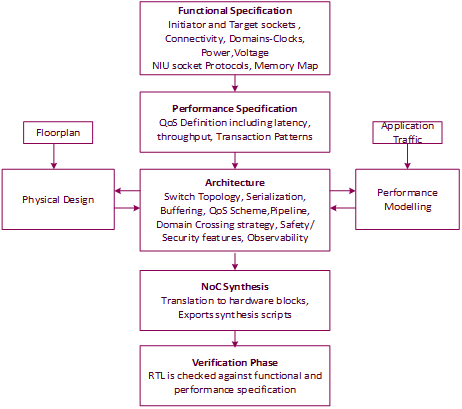
The Functional Specification phase is where the initiator and target NIUs are identified, along with the protocol used for each socket and the connectivity matrix. The subset of the protocol is captured, say the out-of-order or unaligned transfer support. The power and clock domains of the design are configured as part of this step. The memory map of the master and initiator IPs is also defined in this stage.
The Performance Specification is the definition of the quality of service expected from the NoC. The SoC components can be categorized as latency-sensitive (CPU, for example), latency-critical with long-term bandwidth (video) and short-term bandwidth(audio) requirement, and the best effort traffic (ethernet). The traffic scenarios and the data flow is clarified at this stage that is in turn used in the performance modeling
In the Architecture phase, hardware resources are allocated in the NoC, defining how transaction flows are muxed and de-muxed using switch topology, the degree of serialization, buffer size, arbitration schemes for ensuring QoS, pipeline stages location, clock and power crossings location, etc. The safety and security requirements and the debug features are also identified at this stage. The architecture can be simulated against the previously defined scenarios to determine, on the one hand, if the scenario performance criteria are met, and on the other hand, what are the saturated or under-used resources in the NoC. This is an iterative process where the architecture is fine-tuned to deliver an optimized solution based on modeling. The interaction with the physical design at this stage will ensure that there are no surprises during back-end design phase.
This phase is the most time-consuming phase of the design flow that involves significant parameters of NoC design, and some of these are captured below
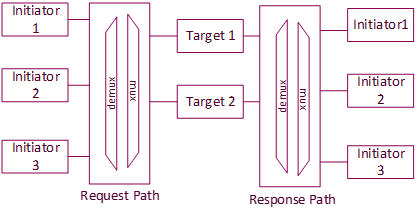
- Topology Creation:
Based on the connectivity matrix, a switch topology is initially created with all initiators talking to targets using demultiplexers and multiplexers (routing unit), as shown in the Figure 8 .
As a next step, the traffic is grouped by the insertion of links. Choosing the links lets the architect decide what the shared resources are and in which order they are shared. The link is a placeholder to add topology features like serialization, clock domain adapter, buffering, etc
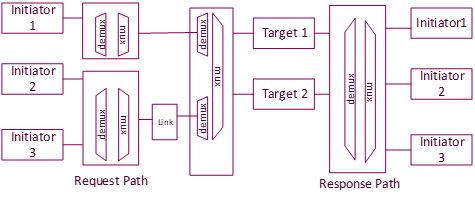
- Rate Adaption:
Buffering is introduced to adapt for differing rates in upstream and downstream traffic. From high to low bandwidth, the packet is stored to prevent upstream traffic congestion. For low to high bandwidth links, the packet is collected before a downstream burst. The buffer size and the resource requirement is decided based on the traffic
- QoS
The QoS scheme enables a priority to be attached to a transaction (urgency) or to all the transactions pending on a socket (hurry). The second mechanism permits us to dynamically raise the priority of a transaction that has already been requested. The arbitration scheme at each mux can also be programmed based on traffic priority. In addition to this, a QoS generator can be attached to the initiator NIU if the initiator protocol doesn’t provide any native QoS support.
- Serialization
The degree of serialization can be defined in the link. For maximum data throughput, serialization can be minimum, whereas, for low bandwidth communication, the number of wires can be reduced by increasing serialization. Another criterion in the decision of serialization is the distance between the blocks.
- Clock/Power Adaption
There are different adaption schemes available for crossing clock and power domains. Adapter units are added based on the scheme used in the architecture. These units can be asynchronous where no relationship is assumed or synchronous where minimal resources are utilized for domain crossing.
- Pipeline
In the architecture description, it is possible to insert pipeline stages almost anywhere along the route, thus providing a provision for SoC timing closure
In the NoC synthesis phase, the NoC is translated into hardware blocks. At the end of this phase, the Register Transfer Level (RTL) description of the NoC can be exported together with synthesis scripts, ready to be integrated, simulated, and synthesized.

In the verification phase, the RTL description is checked against its functional and performance specifications. For functional verification, a test bench and stimuli are generated out of the specification. For performance verification, the scenarios are played against the RTL description of the NoC to verify their performance criteria are met.
Future Trends and Research Area
NoC physical layer is one of the active research topics. The investigations on innovative interconnect technologies such as carbon nanotube (CNT) based, photonic waveguide-based, Wireless, and 3D on-chip communication architectures are going on. There is focused research on exploring novel Networks-on-Chip (NoCs) for different application domains. Developing innovative design automation strategies and tool flow to traverse the complex on-chip communication design effectively is another relevant research area.
Conclusion
A shift in the interconnect design is the need of the hour, and NoC is a promising candidate provided we mature in this design implementation space in the coming years. There are many challenges involved here, including reeducation of the system designers for the new concepts. New flow control methods are required to reduce the area overhead of these networks while maintaining high efficiency. Proposing NoC architectures that excel in different application domains requires a constant focus on appropriate tradeoffs.
References
[1] Abderazek Ben Abdallah, Multicore Systems-on-Chip: Practical Software/Hardware Design, 2nd Edition, Publisher: Springer, (2013) , ISBN-13: 978-9491216916
[2] Guerrier P, Greiner A (2000) A generic architecture for on-chip packet-switched interconnections. In: Proceedings of the design automation and test in Europe conference (DATE), Paris, pp 250–256
[3] Dally, W. J. Towels, B. (2001) Route packets, not wires: On-chip interconnection networks. In Proceedings of the 38th Design Automation Conference.
[4] Benini L, De Micheli G (2002) Networks on chips: a new SoC paradigm. IEEE Comput 35(1):70–78
[5] Zeferino CA, Kreutz ME, Carro L, Susin AA (2002) A study on communication issues for systems-on-chip. In: Proceedings of the 15th symposium on integrated circuits and systems design (SBCCI), Porto Alegre, pp 121–126
[6] E.Cota et al, Reliability , Availability and Serviceability Of Network On Chip
[7] Arteris Whitepaper: Comparison of Network On Chip and Buses
[8] Lecler, Jean-Jacques, and Gilles Baillieu. “Application driven network-on-chip architecture exploration & refinement for a complex SoC.” Design Automation for Embedded Systems 15, no. 2 (2011): 133-158.


























42 thoughts on “Network on Chip – an Overview”
Thank you very much for sharing, I learned a lot from your article. Very cool. Thanks.
acheter tadalafil en ligne: derinox sans ordonnance – ventoline sans ordonnance pharmacie
avene cleanance mask: peut on aller chez le cardiologue sans ordonnance – poly-karaya achat en ligne
apotheke nl: medicijn recept – netherlands online pharmacy
medicijnen online: apteka eindhoven – netherlands pharmacy online
https://tryggmed.com/# kompresjonsstrømper apotek
holandia apteka internetowa [url=https://zorgpakket.com/#]apotheek apotheek[/url] medicaties
online apotheker: medicatie aanvragen – medicatie bestellen online
Этот сайт публикует интересные инфосообщения со всего мира.
Здесь вы легко найдёте события из жизни, бизнесе и разнообразных темах.
Информация обновляется ежедневно, что позволяет не пропустить важное.
Простой интерфейс ускоряет поиск.
https://breakmoda.ru
Любой материал оформлены качественно.
Целью сайта является объективности.
Оставайтесь с нами, чтобы быть в центре внимания.
https://snabbapoteket.com/# apotek lasarettet
http://snabbapoteket.com/# analpropp apotek
medicijnen aanvragen apotheek: medicaties – medicaties
hiv-test apotek [url=https://tryggmed.shop/#]apotek -[/url] benzoyl peroxide apotek
koffeintabletter apotek: mГҐlebГҐnd kropp apotek – urin stix apotek
https://zorgpakket.shop/# mijn apotheek medicijnen
id armbГҐnd barn apotek: klyster apotek – sГҐr hals apotek
pincett apotek [url=https://snabbapoteket.shop/#]köpa nässpray[/url] solfjäder engelska
apotek online: online apotheken – apteka online holandia
https://snabbapoteket.shop/# deo till barn
https://snabbapoteket.shop/# www apotek
vilka apotek finns det: apotek bestГ¤lla hem – kylvГ¤ska medicin apotek
amylnitritt apotek [url=https://tryggmed.com/#]varmekrem apotek[/url] apotek glidemiddel
online pharmacy: kroniska sjukdomar lista – proteinpulver rea
https://tryggmed.shop/# apotek utdanning
online recept: farma online – online apotheek – gratis verzending
apotheek aan huis [url=https://zorgpakket.shop/#]apotheek spanje online[/url] online medicijnen bestellen met recept
teip apotek: frikort apotek – ledig stilling apotek
https://zorgpakket.com/# mijn medicijnkosten
https://snabbapoteket.shop/# norsk ä
medicatie online: MedicijnPunt – medicij
pharmacy nederlands [url=https://zorgpakket.shop/#]Medicijn Punt[/url] medicatie kopen
bakteriell vagose apotek: mine resepter apotek – aktivt kull apotek
https://tryggmed.shop/# øyemaske apotek
legit mexican pharmacy for hair loss pills: MediMexicoRx – buy meds from mexican pharmacy
IndiaMedsHub [url=http://indiamedshub.com/#]world pharmacy india[/url] top 10 pharmacies in india
https://expresscarerx.online/# online pharmacy propecia
https://indiamedshub.com/# world pharmacy india
indianpharmacy com: best india pharmacy – best india pharmacy
semaglutide mexico price: buy meds from mexican pharmacy – MediMexicoRx
http://medimexicorx.com/# buying prescription drugs in mexico online
IndiaMedsHub [url=http://indiamedshub.com/#]IndiaMedsHub[/url] IndiaMedsHub
best prices on finasteride in mexico: MediMexicoRx – MediMexicoRx