Automatic Number Plate Recognition (ANPR), also called Automatic License Plate Recognition (ALPR), refers to an accurate image processing system used for detecting and reading vehicle number plates. It uses an Optical Character Recognition (OCR) component on images of number plates that are captured at high speed, to detect individual characters on the number plate and transforms them into digital data.
ANPR is, therefore, the underlying technology used to detect a vehicle license / number plate that, in turn, supplies this information to the next stage of computer processing through which the captured information can be interpreted, stored or matched to create an ANPR based application.
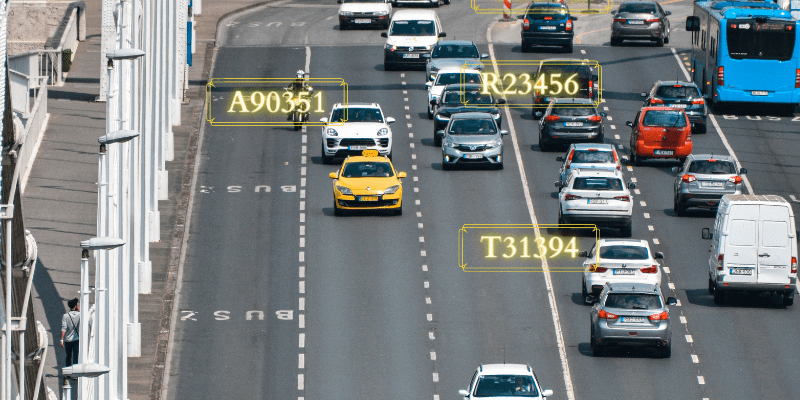
ANPR is being used by law enforcement agencies across countries like the UK, Australia, Germany, France, Denmark, Japan and others for automatic toll collection, traffic law enforcement, parking lot access control, and road traffic monitoring, journey time analysis, bus lane enforcement among others.
Japan has been fast in deploying ANPR systems in patrol cars, helicopters and fixed in strategically important areas. In Japan, fixed ANPR systems are expected to reach a market size of US$44.4 Billion by the year 2025*.
In this blog, we outline how a Japanese license plate is detected and the characters in the license plate recognized. The license plate detection is based on semantic segmentation with a Resnet-type model and character recognition is based on a classifier network. Japanese license plates have certain special features which have to be studied as a first step.
Special Features of Japanese License plates
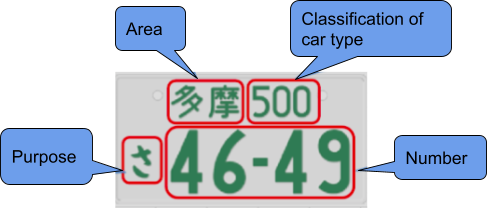
The Japanese license plate consists of 4 main sub portions . The following figure depicts each of the sub regions.
Also different color license plates indicate the engine capacity of the vehicle . The following figure describes different colors and corresponding engine capacity.

The top line contains the name of the issuing office and a vehicle class code. The bottom line contains a hiragana character and a four-digit serial number divided into two groups of two digits separated by a hyphen. Any leading zeros are replaced by centered dots.

Dataset preparation and Labeling
The dataset is created using images from a variety of sources. The following site provides a representative set. [Link]
The training results yield maximum accuracy only if the labels of the region of interest are correct. To ensure this, tight labeling is required. The collected images are then labeled using the LabelMe application. These images and corresponding xml files are used for training purposes.
License Plate Detection and Classification

Fig.3 Vehicle Detection Pipeline
We describe the above pipeline with respect to a sample input image:
YOLO cropping

Fig.4 Raw input image
The first step in ANPR is to detect and isolate the vehicle from the background, from the raw input images. Here we have used the Tiny YOLO (You Only Look Once) v3 model for the purpose of object detection. Reasoning behind choosing YOLO is due to it’s fast, accurate and multi-scale predictions. An important criteria here is that it is a real-time object detection system. The objects we are interested in range from cars, buses to trucks. Detections such as roads, hills, people and the like are discarded as they aren’t of interest in our use case. Using Tiny YOLO, we extract the vehicle crop.

Fig.5 Vehicle crop generated using YOLO
License Plate Detection module
The vehicle crop is passed onto a semantic segmentation model, which in turn extracts the number plate region. These number plate bounding regions can be stored in suitable format such as ((x1, y1), (x2, y2)) or (x, y, w, h) in a json file.

Fig.6 License Plate crop
License Plate Crops
Semantic segmentation also generates relevant masks for area, color, digit and purpose. This semantic segmentation model is trained on the Japanese License Plate dataset so as to generate these masks. Similar to the previous step, here too the masks are stored in a suitable format in a json file.
{“align”:”center”,”id”:31265,”sizeSlug”:”large”,”linkDestination”:”none”} –>

Fig.7 Masks for area, color, digit and purpose
OCR prediction
The next stage requires us to apply Optical Character Recognition (OCR) onto these mask areas. This stage returns the predictions of features of interest on the specific number plate. These predictions are based on the following classes:
Color
[‘black’, ‘white’, ‘green’, ‘yellow’]
Area
[‘shizuoka’, ‘fukuoka’, ‘fukushima’, ‘gifu’, ‘gunma’, ‘hiroshima’, ‘kanazawa’, ‘kitami’, ‘kochi’, ‘nilgata’, ‘obihiro’, ‘oita’, ‘tokushima’, ‘toyama’, ‘utsunomia’, ‘okayama’, ‘sappora’, ‘sendai’, ‘numazu’, ‘chiba’, ‘yamanashi’, ‘tama’, ‘osaka’, ‘yokohama’, ‘maebashi’, ‘nerima’, ‘wakayama’, ‘kobe’, ‘miyazaki’, ‘saitama’, ‘kumagaya’, ‘shinagawa’, ‘nara’, ‘adachi’, ‘kyoto’, ‘naniwa’, ‘himeji’, ‘kawasaki’]
Purpose
[’13’, ‘2’, ’20’, ‘7’, ‘1’, ’17’, ’10’, ’25’, ’12’, ’18’, ’21’, ‘5’, ‘4’, ’24’, ’23’, ’16’, ’15’, ’22’, ’19’, ‘3’, ‘8’, ‘9’, ’14’, ‘6’, ’11’, ’26’, ’27’, ’28’]
Digit
[‘2’, ‘7’, ’00’, ‘1’, ’90’, ‘0’, ‘5’, ‘4’, ‘3’, ‘8’, ‘9’, ‘6’, ’13’, ’18’, ’22’, ’23’, ’33’, ‘100’]
Below are the predictions generated by our pipeline for the sample test image:
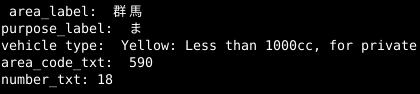
Fig.8 Predicted console result

Fig.9 Annotated result number plate
Conclusion
This article introduces our deep-learning based ANPR pipeline that is capable of automatically detecting vehicles, cropping out their license plates and recognizing Japanese characters and all other relevant fields. The production version of our ANPR software can integrate with cost-effective IP or web cameras and perform real-time automatic plate reading using cost effective compute systems – thus allowing their deployment in a host of practical applications.
For more use cases of our Vision AI powered software, read our blogs on Automatic Container Code Detection, Face Mask and Attire detection and Automated Tyre Defect Detection.


























45 thoughts on “Vision AI powered Automatic Number Plate Recognition (ANPR) for Japan”
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
I visited a lot of website but I think this one has something extra in it in it
I’ve been using sativa tincture daily seeing that on the other side of a month for the time being, and I’m indubitably impressed before the sure effects. They’ve helped me perceive calmer, more balanced, and less anxious in every nook the day. My forty winks is deeper, I wake up refreshed, and sober my focus has improved. The trait is excellent, and I cognizant the sensible ingredients. I’ll obviously carry on buying and recommending them to the whole world I recall!
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
cialis en pharmacie sans ordonnance: coupe faim en pharmacie sans ordonnance – anti stress pharmacie sans ordonnance
bh rГ¶d: orolig mage gravid – paracetamol barn
https://zorgpakket.shop/# aptoheek
apotek kundtjГ¤nst: SnabbApoteket – kГ¶pa hГ¶rapparat pГҐ nГ¤tet
landelijke apotheek [url=http://zorgpakket.com/#]MedicijnPunt[/url] betrouwbare online apotheek
https://snabbapoteket.shop/# apotek rea
bestellen apotheek: online medicijnen – dutch apotheek
https://snabbapoteket.shop/# destillerat vatten apotek
nad apotek: Trygg Med – apotek bandasje
medicijnen apotheek [url=http://zorgpakket.com/#]apotheker online[/url] medicijnen online kopen
https://snabbapoteket.shop/# hård i magen apotek
mammaklГ¤der rea: SnabbApoteket – apotek finland leverans sverige
online medicijnen bestellen: Medicijn Punt – online apotheek nederland met recept
https://tryggmed.com/# apotek vaksine influensa
online apotheek zonder recept ervaringen [url=https://zorgpakket.com/#]Medicijn Punt[/url] online pharmacy netherlands
https://zorgpakket.com/# online apotheek gratis verzending
apotek ГҐpningstider jul: eye pads apotek – apotek for alle
apotek ГҐpent 1 juledag: Trygg Med – kulltabletter apotek
sura uppstötningar barn 8 är [url=http://snabbapoteket.com/#]Snabb Apoteket[/url] svinkoppor i hårbotten
https://zorgpakket.com/# onlineapotheek
ormekur katt apotek: TryggMed – magnesiumsitrat apotek
borvann apotek: pulsoksymeter apotek – alun apotek
https://zorgpakket.com/# onlineapotheek
http://zorgpakket.com/# pharmacy online
online apotheek 24 [url=https://zorgpakket.shop/#]apotheken[/url] apotheke niederlande
anti dandruff shampoo apotek: apotek vaksine – apotek ГҐpent 1 mai
snacks nГ¤r man Г¤r sjuk: Snabb Apoteket – ШµЩЉШЇЩ„ЩЉШ© Ш§Щ„ШіЩ€ЩЉШЇ
https://snabbapoteket.com/# när slutar gratis tandvård
resepter apotek [url=https://tryggmed.shop/#]Trygg Med[/url] krykker apotek
apotek no: TryggMed – influensavaksine pГҐ apotek
vitamin c apotek: Trygg Med – influensavaksine 2021 apotek 1
https://zorgpakket.shop/# apotheek online nl
http://indiamedshub.com/# online pharmacy india
ExpressCareRx [url=https://expresscarerx.online/#]flonase new zealand pharmacy[/url] boots pharmacy voltarol
buy antibiotics over the counter in mexico: accutane mexico buy online – MediMexicoRx
best prices on finasteride in mexico: MediMexicoRx – online mexico pharmacy USA
https://indiamedshub.com/# Online medicine home delivery
provigil mexican pharmacy [url=https://expresscarerx.org/#]abc online pharmacy[/url] usa online pharmacy
gabapentin mexican pharmacy: MediMexicoRx – buy from mexico pharmacy
http://expresscarerx.org/# tamiflu online pharmacy
https://expresscarerx.org/# cialis us pharmacy online