
With the skyrocketing number of devices that are being used at home, work and play, consumers are moving away from pressing buttons to using voice UI to control these devices. As voice sensing is becoming a must-have feature in devices, voice-enabled applications are proliferating with a vast majority of Audio AI deployments being done on low-cost microcontroller-based battery-powered edge devices.
Addressing this space is Septra™, Ignitarium’s Audio ML platform. Septra™ contains a host of key software IP components for Noise Suppression, Voice Activity Detection, Voice Command Recognition and Sound Event Classification. Validating these components for deployment readiness on different MCU platforms is a complex task. The Septra™ test jig is a hardware-software test infrastructure purpose-built to thoroughly evaluate the functionality and performance of individual components as well as the end-to-end audio pipeline.
In this blog, we describe the use of the Septra™ Test Jig for validation of our Voice Command Recognition pipeline on MCU platforms. Multiple versions of ARM Cortex-M series, Renesas RX and DSP cores have been used as hardware targets.
Objectives
The automated test jig for a voice command engine has the following main objectives:
- To check the functionality of the software algorithms and the complete audio pipeline
- To check the performance of the algorithms with real time audio under noisy conditions.
- To find the accuracy of algorithms for different wake words, keywords and languages.
- Test the algorithm on different microcontroller platforms.
Test-Jig components
The Test-jig has two main components:
- The microcontroller which hosts the audio algorithms to be tested.
- The PC side Python application that initiates and orchestrates the testing.
The microcontroller is flashed with an application firmware which links the audio algorithm to be tested. Once the application firmware is compiled, this needs to be flashed into the respective platform and ensure that the DUT is ready.
The PC side application is a command line based application written in Python. This application controls the entire test-jig functionality and generates the test report per audio sequence that is fed in.
Both the PC application and the microcontroller communicate over the UART / USB interface using a custom protocol.
The test-jig is capable of testing the algorithm in two modes.
- Mode-1: File based test
- Mode-2: Real-time audio based test
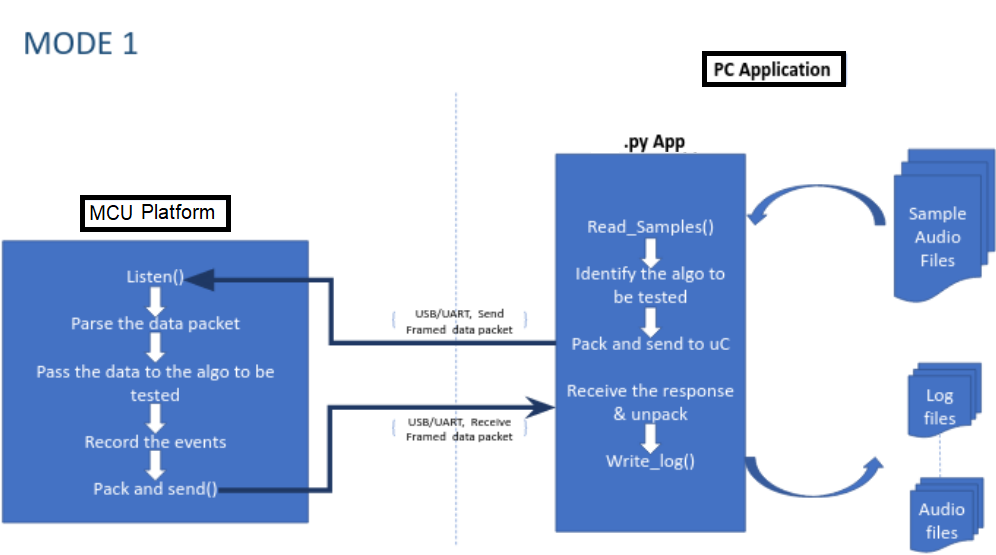
In Mode 1, the audio test sequences are fed to the PC application which then converts the same into byte format and sends it across the UART interface for the algorithm testing. The result of the testing (predicted keywords in this use case) is aggregated within the microcontroller memory and shared back to the PC application once requested. The test results from the DUT are then formulated and verified on the PC side thus finally generating the consolidated test result and the accuracy metrics.

In Mode 2, the data to test the algorithm comes from the Mic which is live fed to the algorithm residing within the microcontroller. The result of the predictions is evaluated internally by the microcontroller and buffered until the PC application requests. The consolidated report generation and accuracy report generation method remains the same as in Mode 1.
Test-Jig outputs
Mode1 (File based Test):
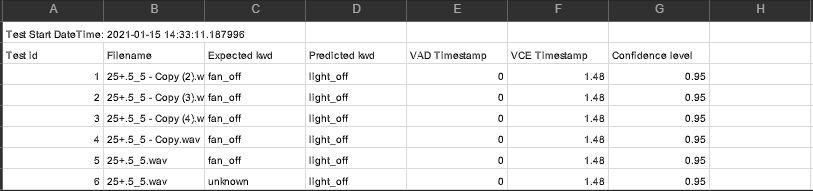
Output will be a .csv file.
With columns as:
Testid, Filename, Expected keyword, Predicted keyword, VAD Timestamp (milliseconds), VCE Timestamp (milliseconds), Confidence
VAD Timestamp signifies the position in time when the Voice Activity Detection algorithm triggered. VCE Timestamp signifies the position in time when the Voice Command Engine triggered prediction of the incoming keyword.
Mode2 (Mic based testing):
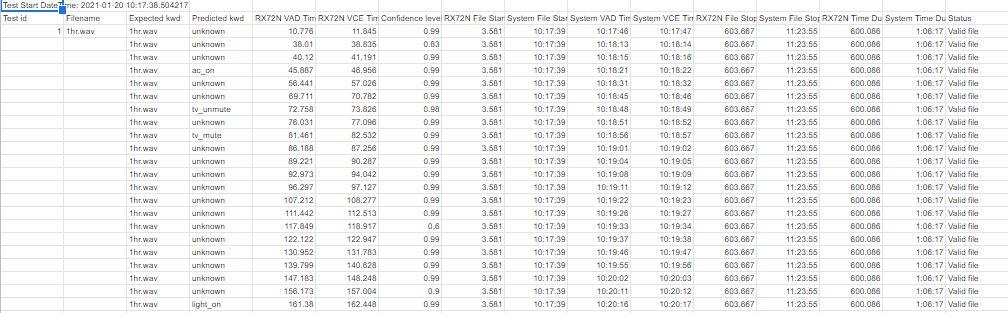
Output will be a .csv file
With columns as:
Testid, Filename, Expected keyword, Predicted keyword, VAD Timestamp (ms), VCE Timestamp (ms), Confidence, RX File Start time (hh:mm:ss:ms), System FileStart time (hh:mm:ss:ms), System VAD Time (hh:mm:ss:ms), System VCE time (hh:mm:ss:ms), RX File stop time (ms), System File Stop time (hh:mm:ss:ms), Status
The first 7 columns are the same for Mode1 and Mode2. The remaining columns are additional timestamps. The real-time, over-the-air nature of incoming speech samples in Mode 2 mimics real life, requiring additional information to correlate ranges of time during which various algorithms are expected to trigger or generate predictions.
A comprehensive report is then generated automatically in xls format:


The generated report will also capture accuracy metrics that can be tuned for the specific context of the application. The above example captures a Voice Command Recognition use case targeted to a specific consumer appliance:
TP(Total)-True positive: % of correctly recognizing actual commands and correctly ignoring random (unknown) words
TP(Commands only)-True Positive:% of correctly recognizing actual commands when there were no random (unknown) words
FP(Total)-False Positive:% of triggering the wrong command where there were actual commands and random (unknowns) words
FP(Commands only):False Positive:% of triggering the wrong command when there were no random (unknown) words
FN(Total)-False Negative:% of actual commands being incorrectly ignored (no action on appliance)
FN(Commands Only)-False Negative: % of actual commands being incorrectly ignored (no action on appliance) where there were no random (unknown) words
In summary, the Septra™ Test Jig infrastructure provides a robust means to test any kind of audio or speech related algorithm on multiple hardware platforms with high levels of automation.
Curious to know more about Ignitarium’s Septra™? Visit our Audio AI Solutions page here.
Related blogs:
‘A new lightweight CNN model for Automatic Speech Command Recognition on Microcontrollers’
‘Simulating Real World Audio for a Voice Command Engine’


























1 thought on “Automated Test Jig for Edge-based Voice Command Engines”
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?